



We casted a webinar to introduce the new version of our platform, now centered on MLOps, and more precisely, on CVOps–MLOps applied computer vision. At Picsellia, we offer an end-to-end computer vision (CV) platform that lets you manage AI data, run experiments, deploy models into production and monitor them with automated pipelines.
To introduce you to Picsellia’s new features, we’ve prepared a use-case in collaboration with the Toulouse Cancer Research Center. If you’d like to watch a replay of our webinar, it’s available on youtube, right here!
Summary
- About the use-case
- Annotating your dataset
- Training your model
- Launching the experiment
- Exporting the model
- Deploying the model
- Making predictions/inferences
- Training a model on a custom dataset of fibroblast nucleus
- Continuous training and alert system
- Comparing shadow models
About the use-case
The use-case was possible thanks to the Toulouse Cancer Research Center, whose collaborators shared with us some of their obstacles for testing and researching.
The center is studying the propagation of cancer cells under microscopes, and researching how some other cells that are natively in our body, called fibroblasts, are helping cancer propagate.
Nowadays, what scientists measure regarding propagation is global fluorescence. By activating some enzymes on the cells, they can monitor the global fluorescence of an image. But, this fluorescence must be reported to the number of cells in the photo to have significant results.
Just counting the cells of an image, can take from 2–3 hours, up to 10–12 hours a week, hampering their research process.
At Picsellia, we thought that AI and computer vision could help them in detecting those cells’ nucleus and automating the cell counting process, bringing the 10-hour counting process to something like 2–3 minutes for a thousand of images.
Methodology
In short, we’ll try to train a new model that will serve as a base-model on our dataset, and we will fine tune it and use it to pre-annotate our images and see how it performs. Our dataset was suited for segmentation but we will use it for object detection just to make the use case simpler, and because object detection is suited for cell counting.
Annotating your dataset
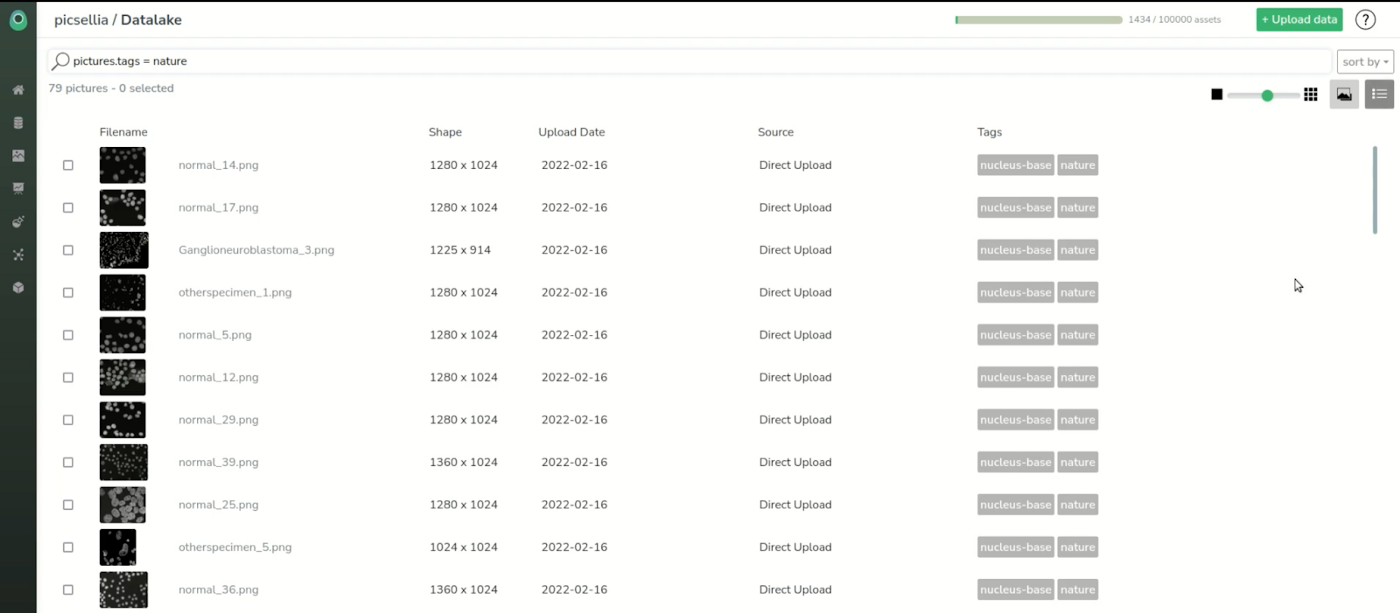
We’ll start in the data lake. This is where all the assets stored can be viewed and searched, for example by tag or other attributes.
Here we have many more images than needed for our use case so we’re going to filter only the images from the Nature dataset, by the tag “nature”.

We see that we only list 79 images, which is the size of the original dataset. We can also switch to a list view and see the filename and attributes of images.
Now we need to select them all and create a Picsellia dataset that we’ll call “empty_images”.
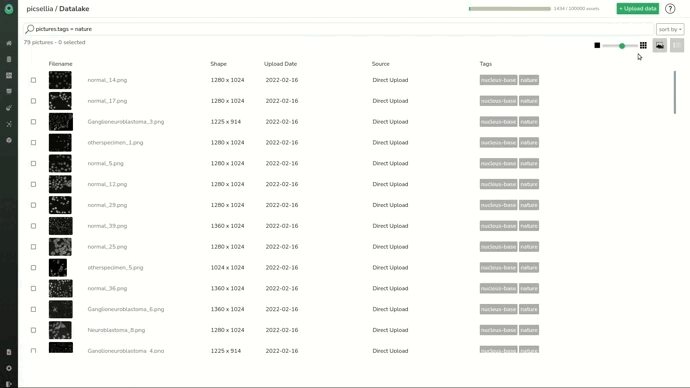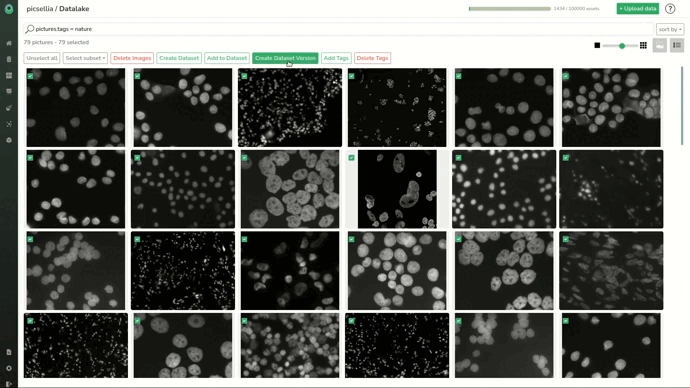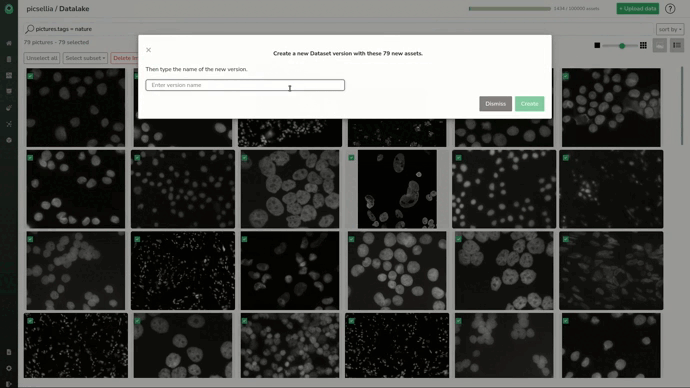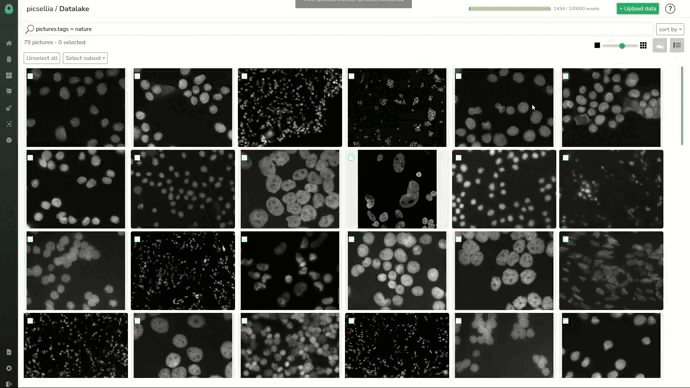
As it should be created now, we can head to the dataset. Let’s select the dataset we want and the “empty_images” version we just created.
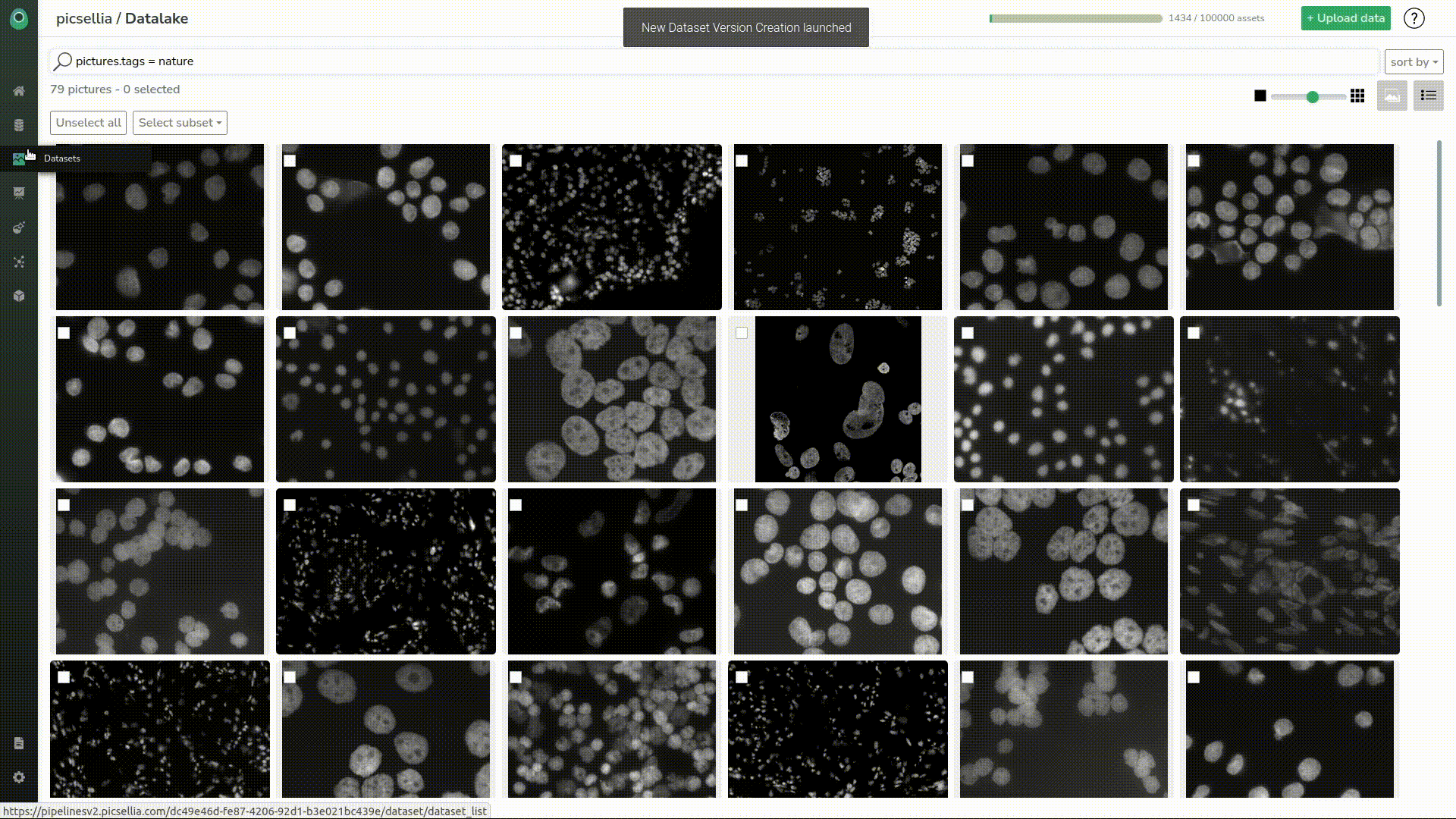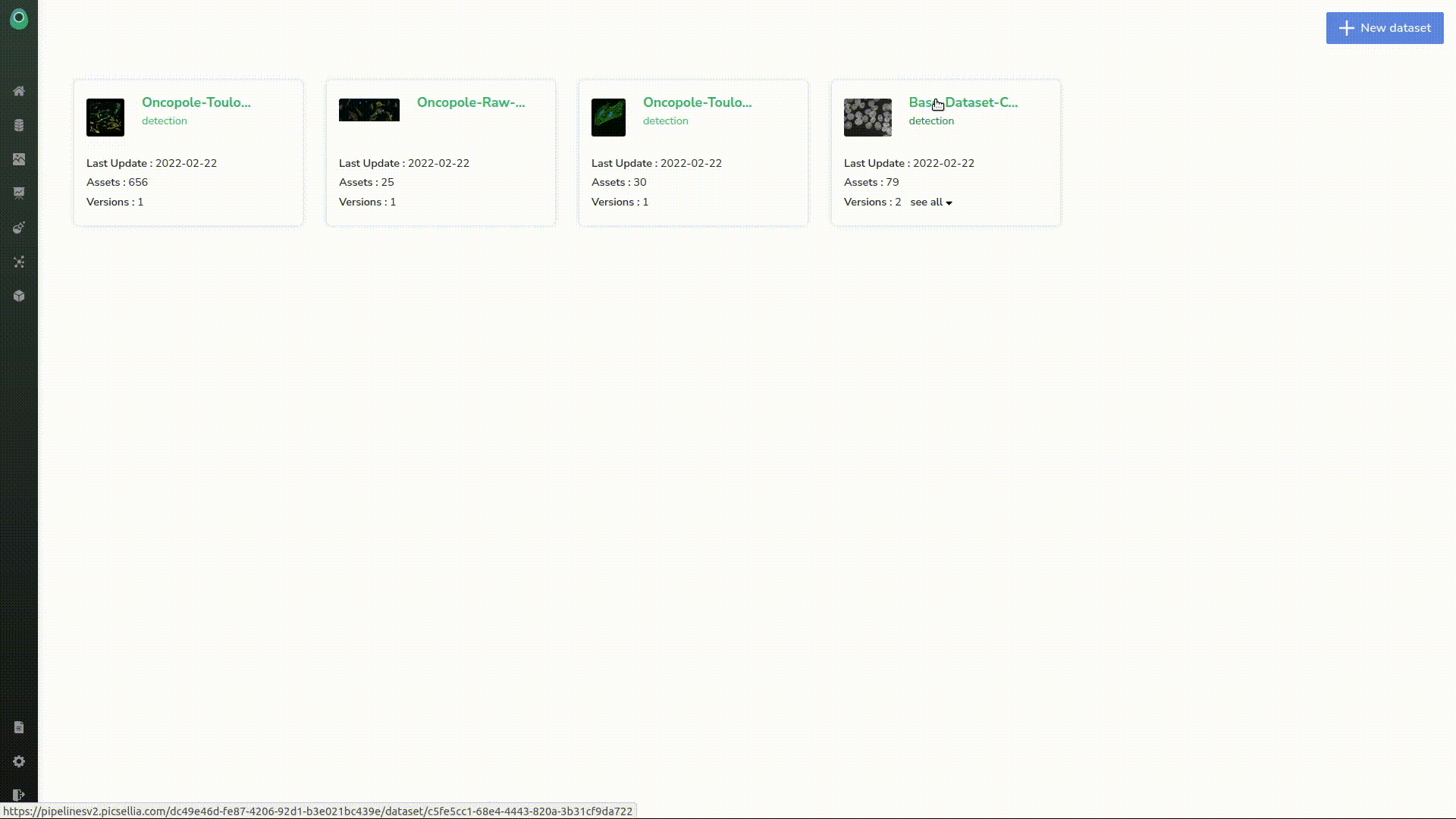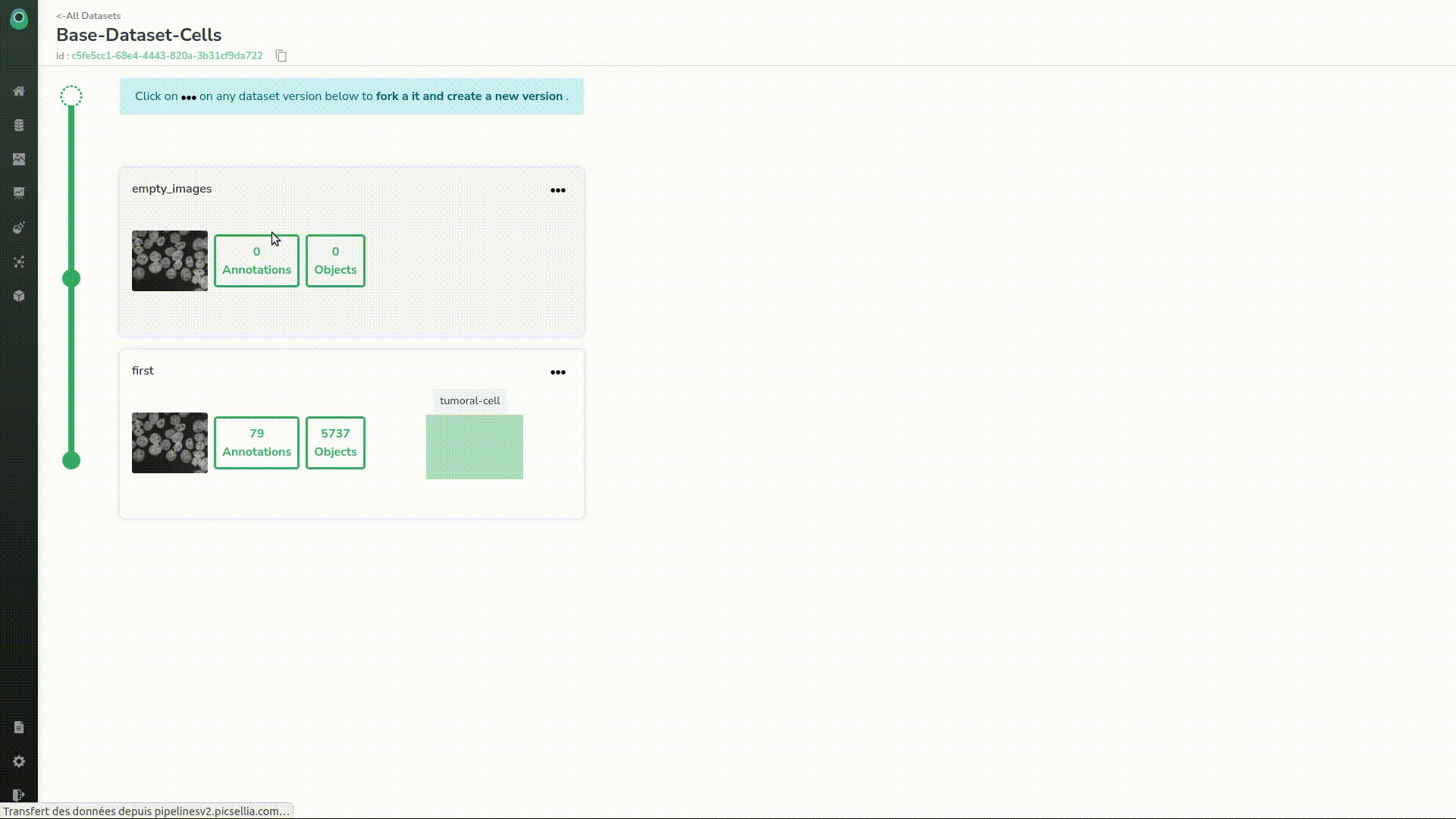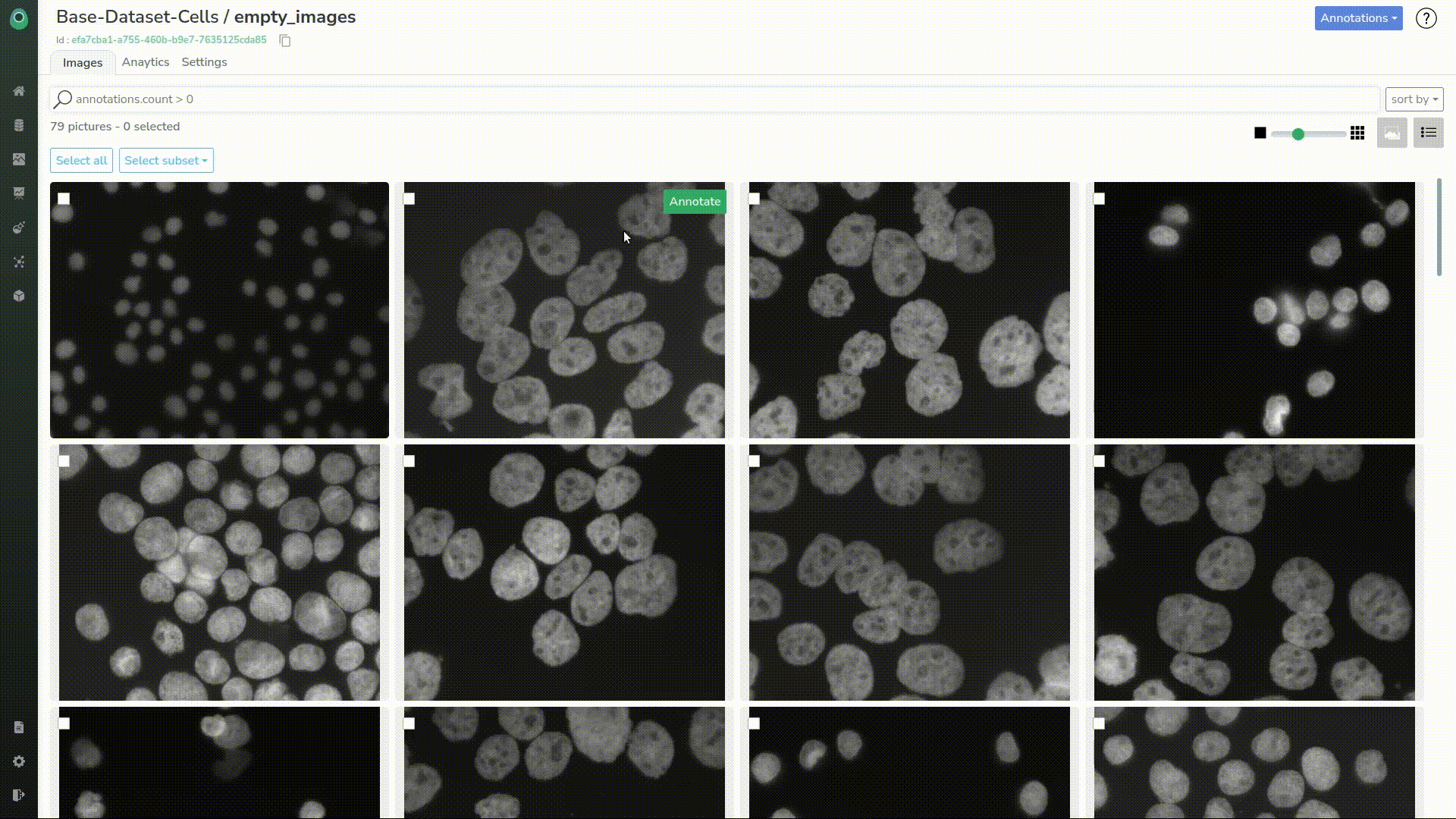
In a dataset, you can import annotations. As the nature dataset was already labeled, we imported the annotations into a new version of our dataset.

We go back to our datasets, and choose the one that is already annotated.
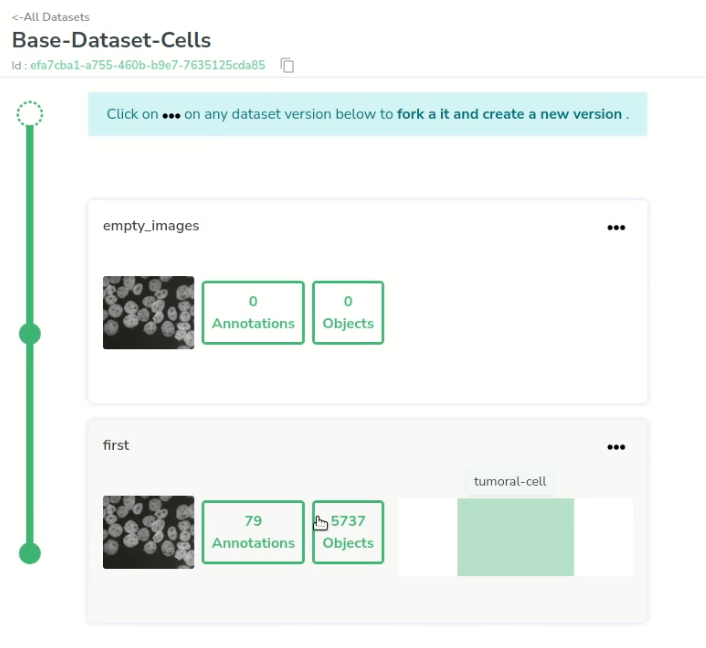
Once there, we can visualize all the annotations that were made. The consistency looks pretty good and all the cells are labeled.

If we select one image and go to our annotation tool, if needed, we can edit the annotations one by one, or create a new annotation with our collaborative annotation interface.

As shown next, in the data lake you can filter your images by attribute, including objects in the annotations. For example, we can choose to visualize all the images that contain more than 20 cells annotated, and see that it narrows down the number of images to 56.

Training Your Model
Now that we are happy with our fully annotated dataset, we can move on to model training.
Let’s create a new project. We’ll call it base-nature-cells, invite our team, and validate it.
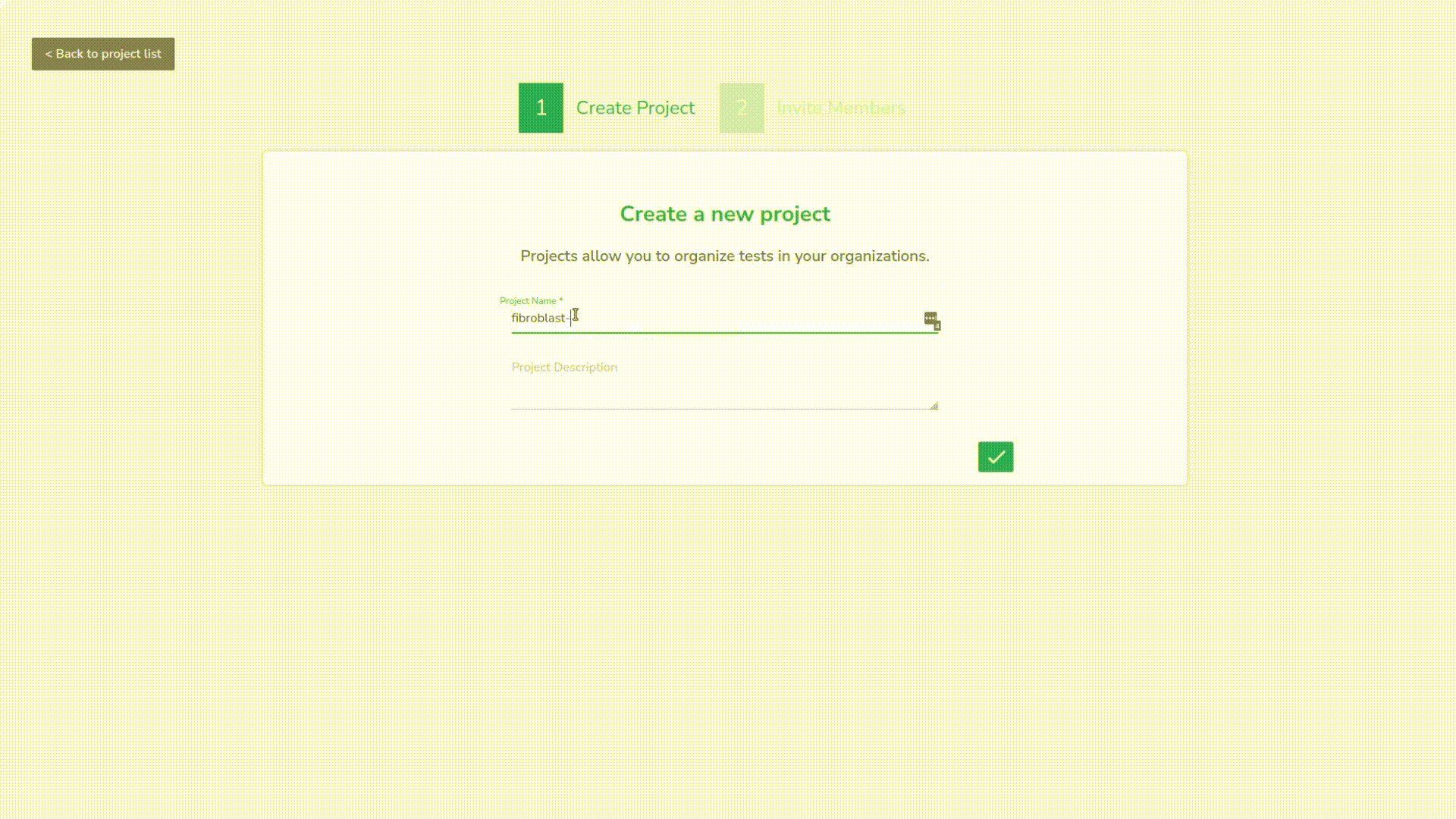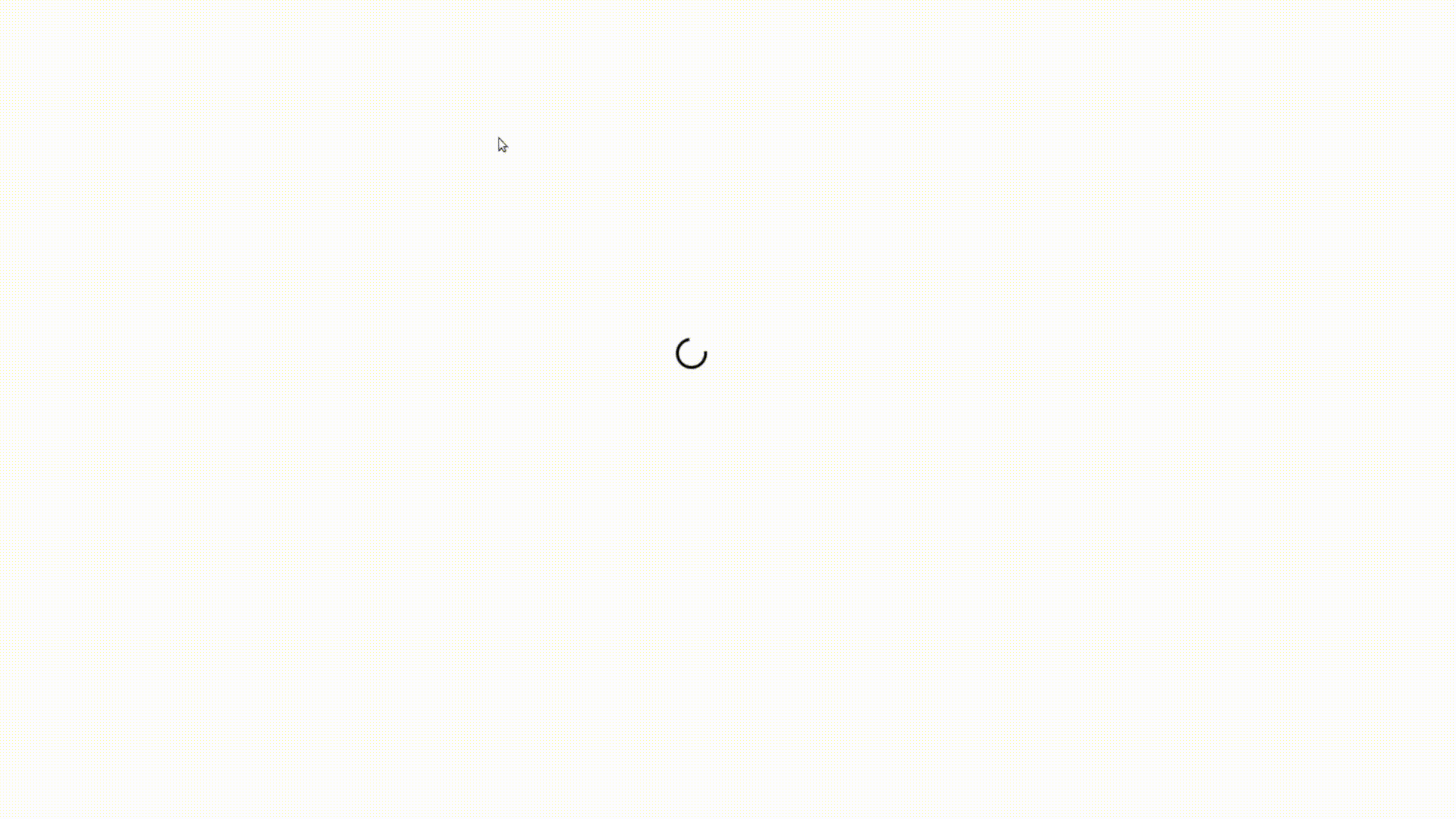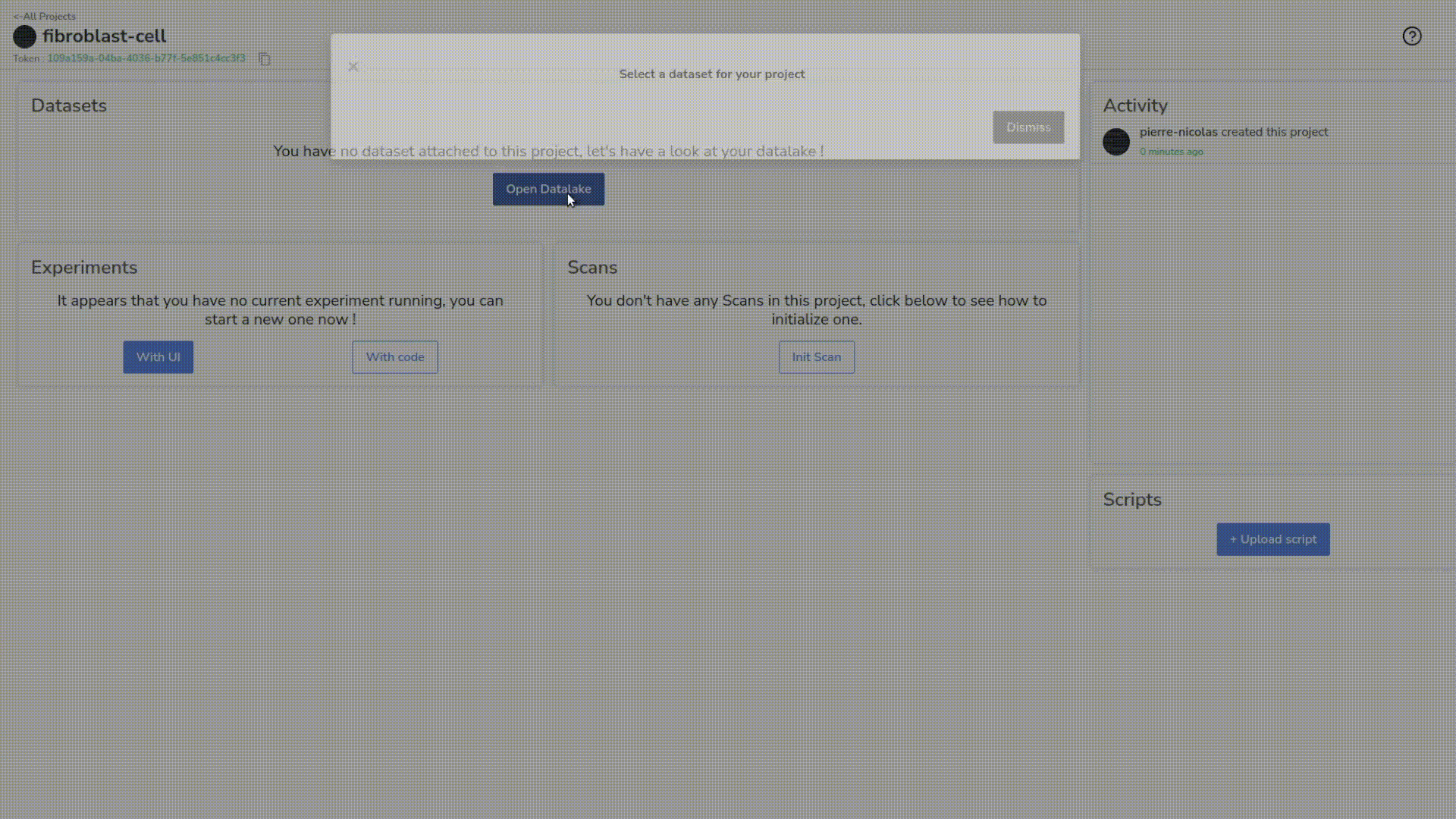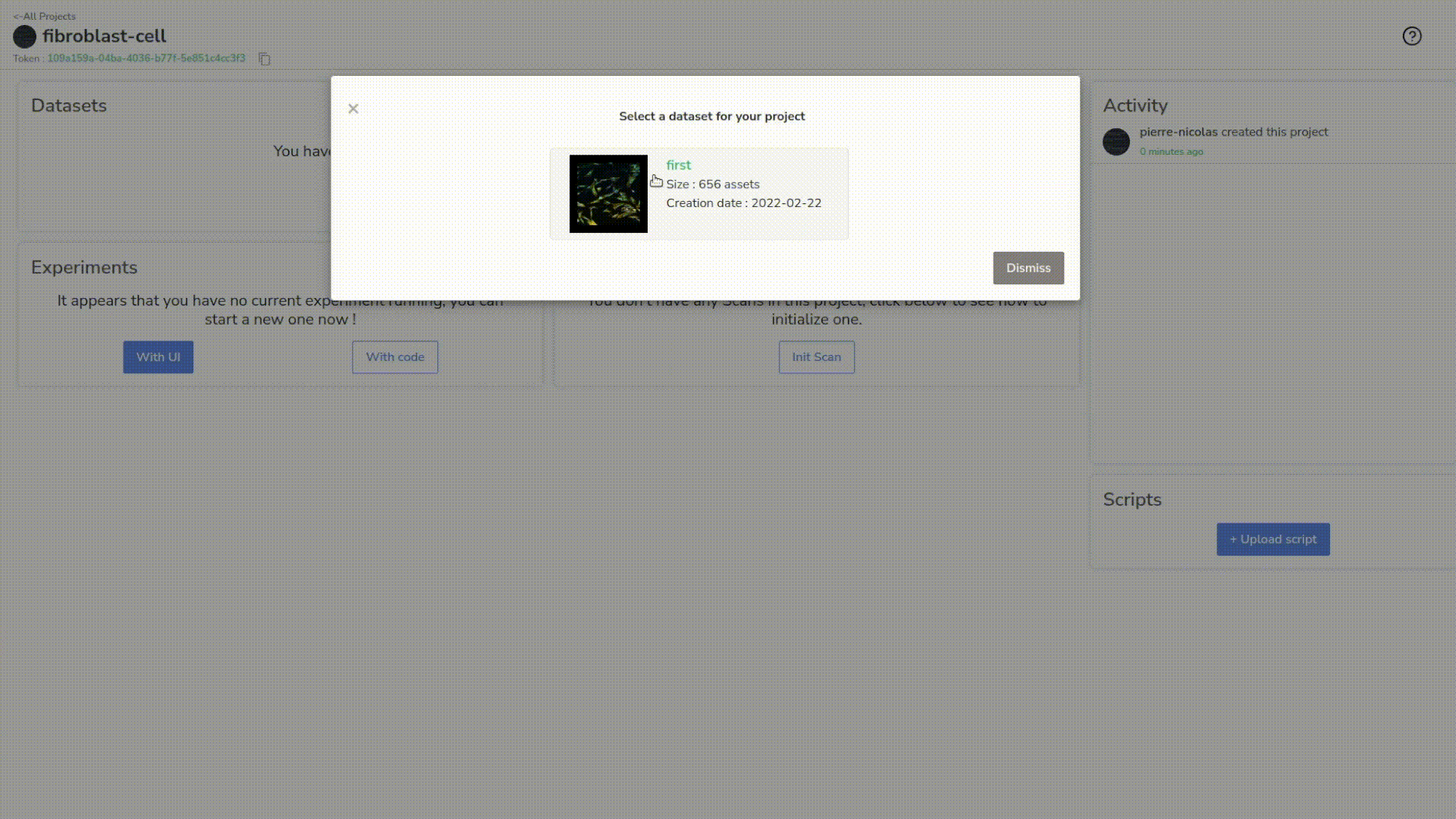
Next, we’ll attach the dataset we just created (with the annotations) to our project, and that will be the source of the experiment we’ll create right now.
Let’s call it v0 and choose in our model HUB an efficientDet-d2 model suited for object detection.

We’ll keep the base parameters for now, select our dataset and create our experiment.
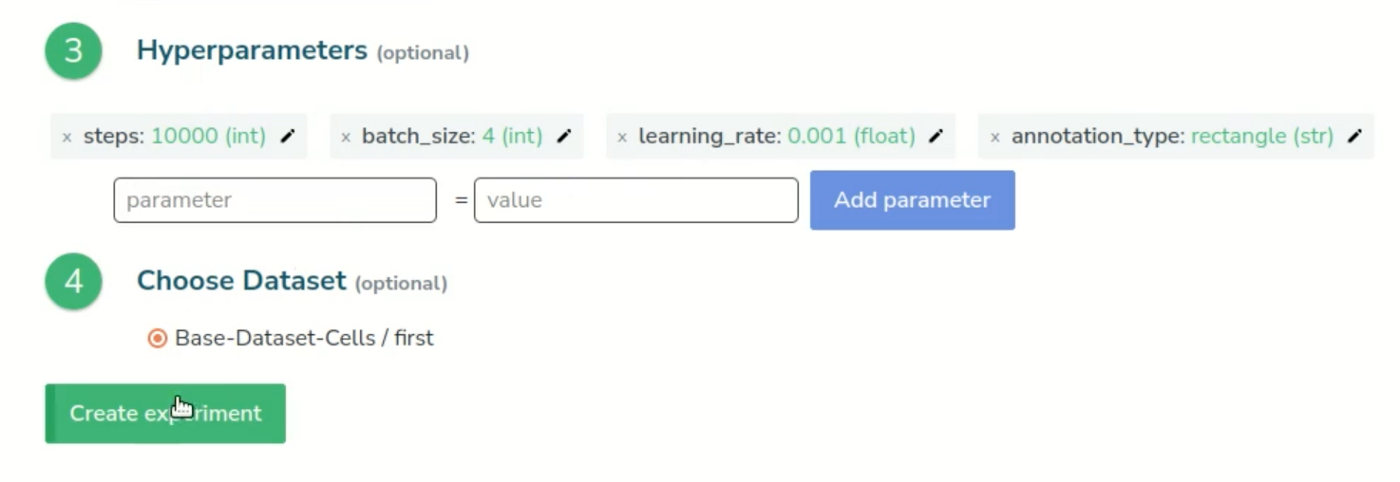
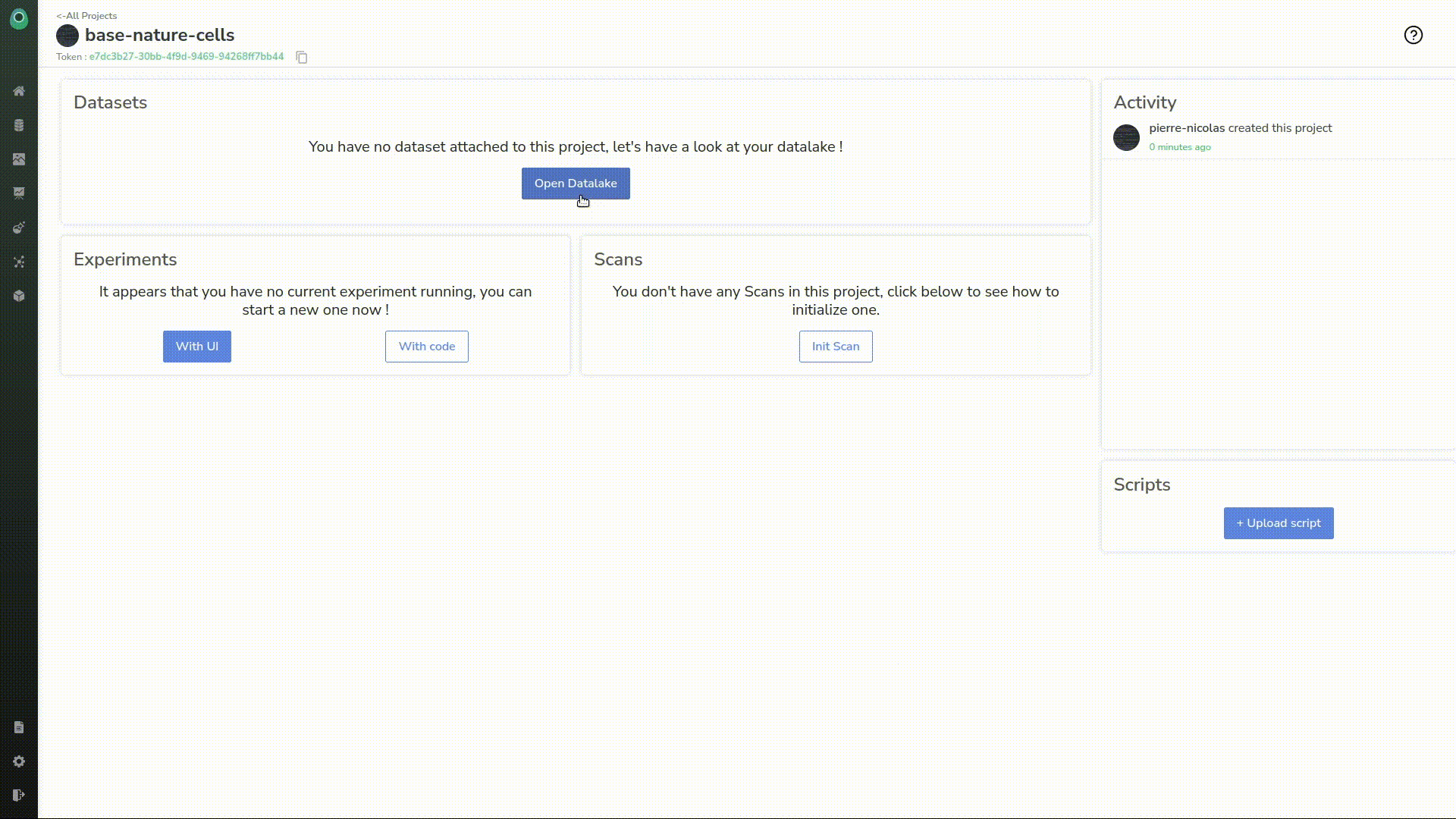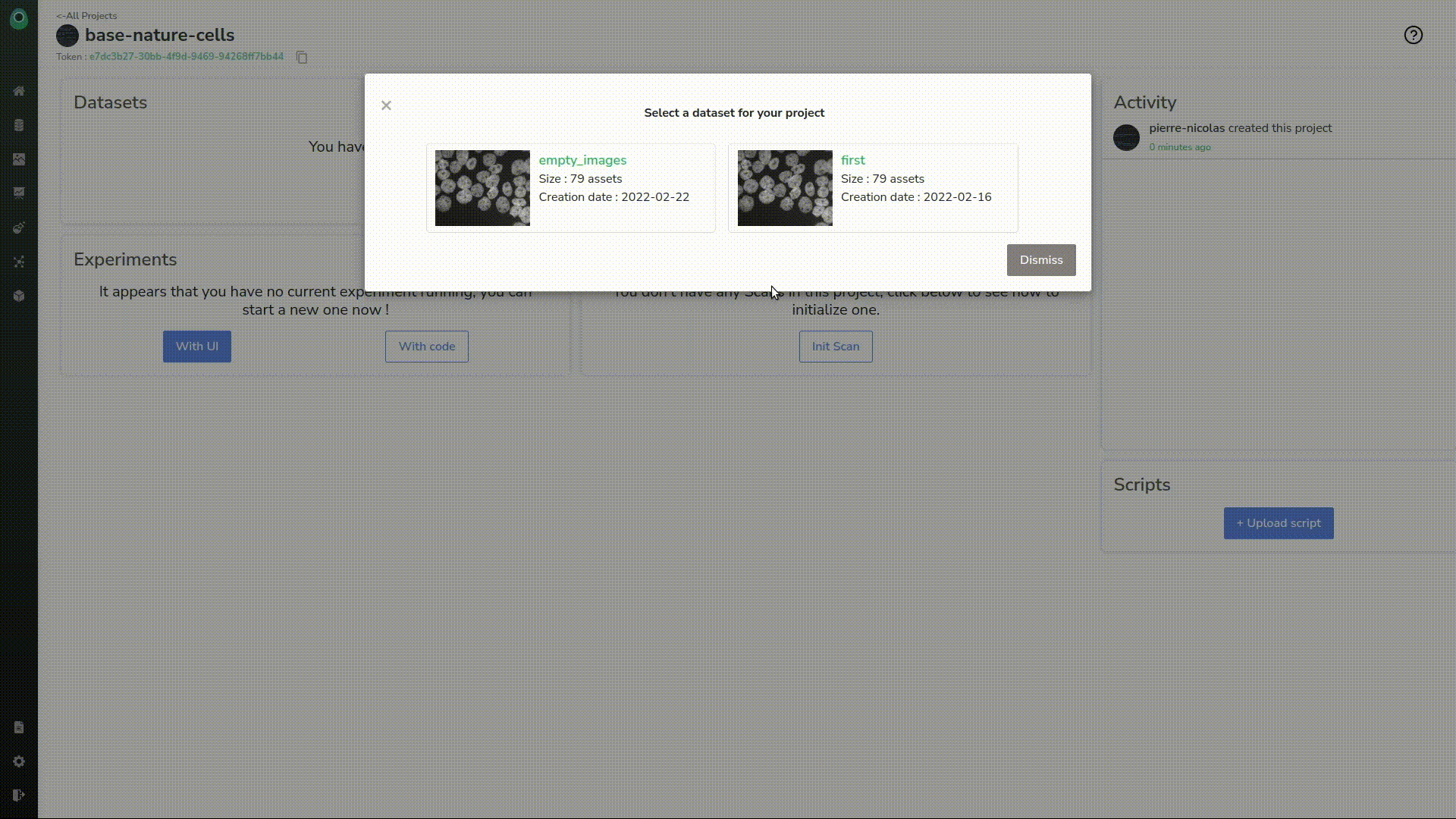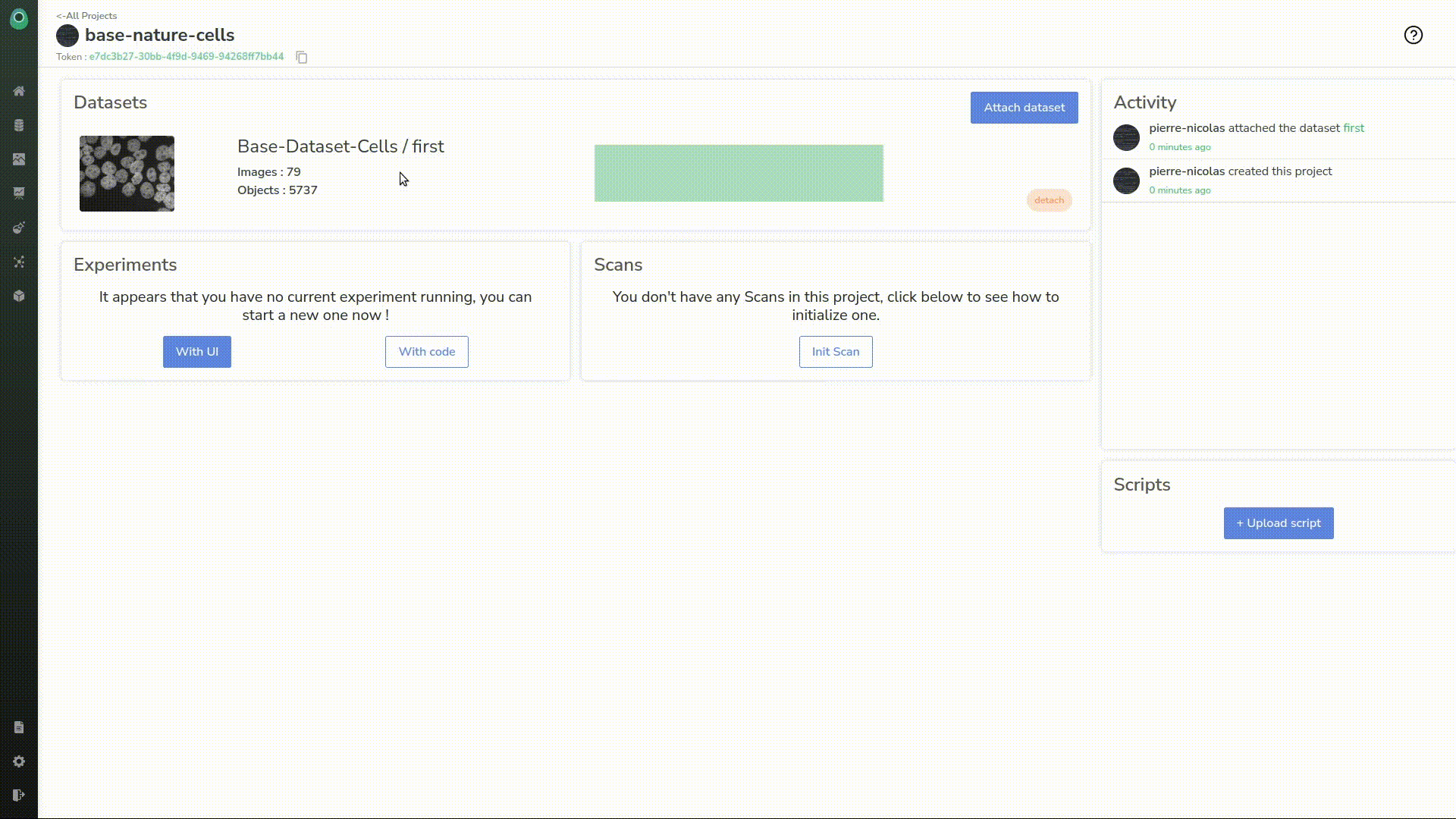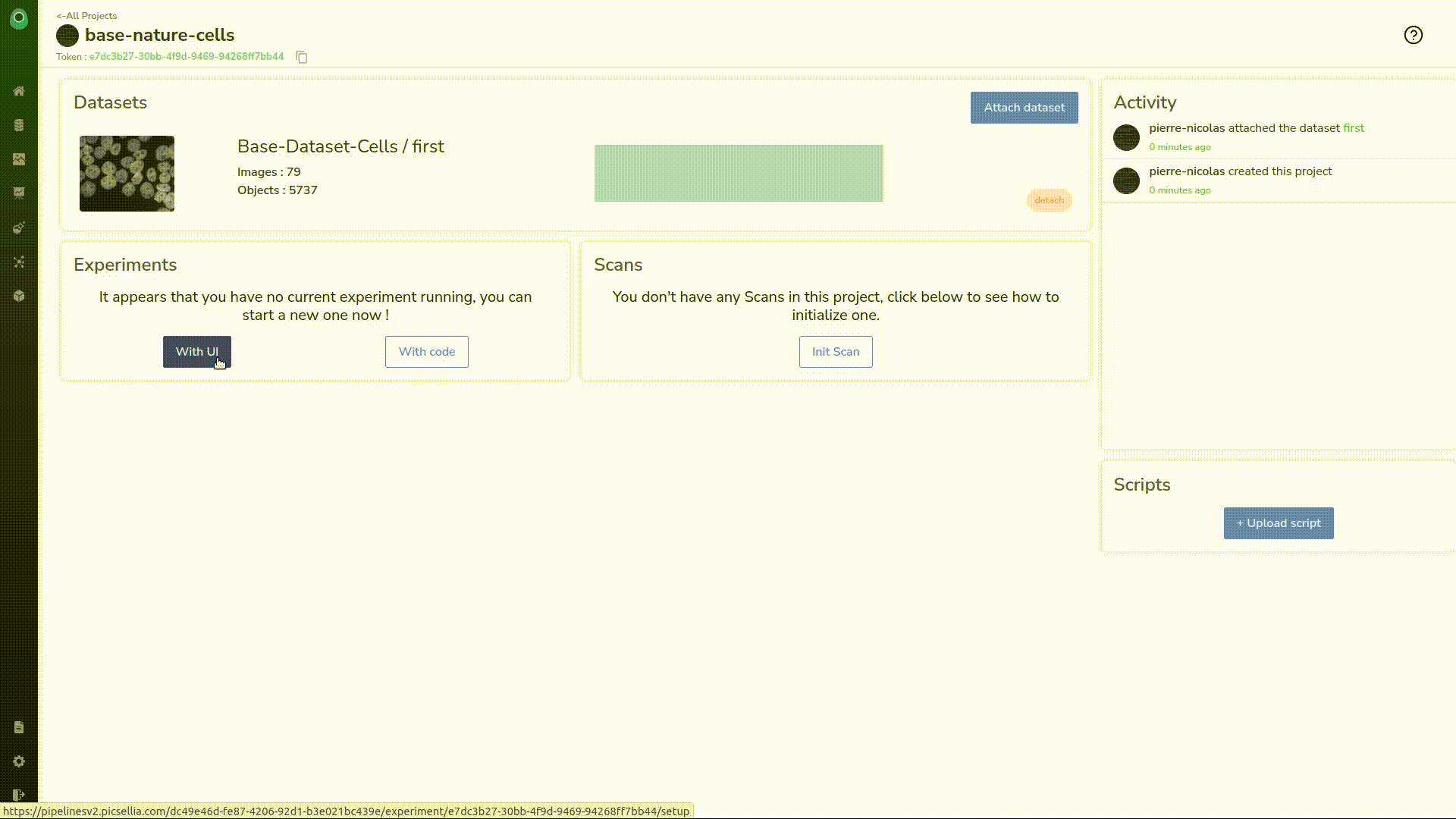
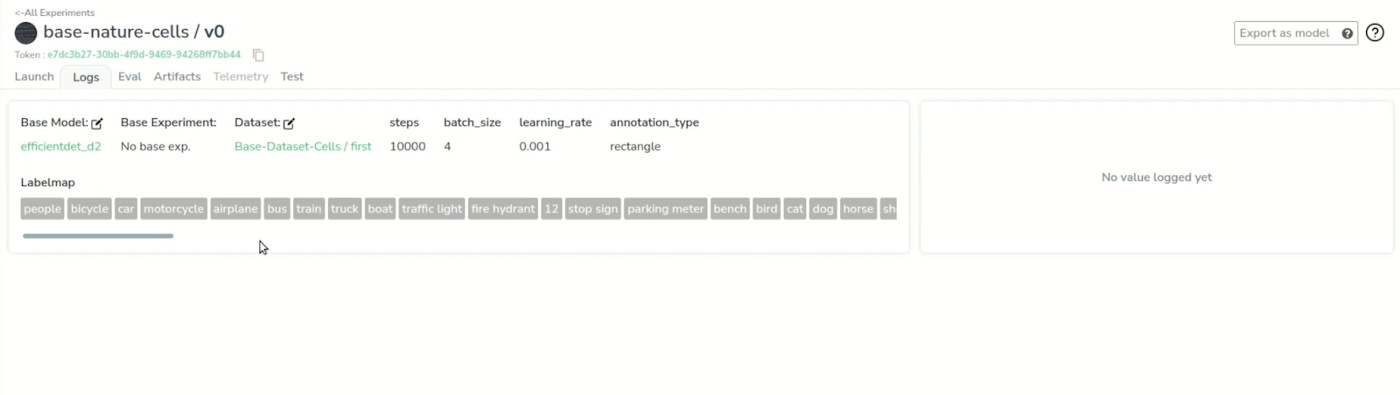
This is our experiment dashboard. It’s empty for now but we can already check that it has attached all the resources we need, such as the base model, the dataset, and the parameters.
Launching the experiment
Now, we want to launch our experiment remotely just by going to the “launch” tab, and click the “launch” button. Picsellia already offers some packaged code for the models in our hub allowing us to launch training seamlessly.
We can now head to the “telemetry” tab where we can see the GPU server logs in real time and make sure that our model is training correctly.

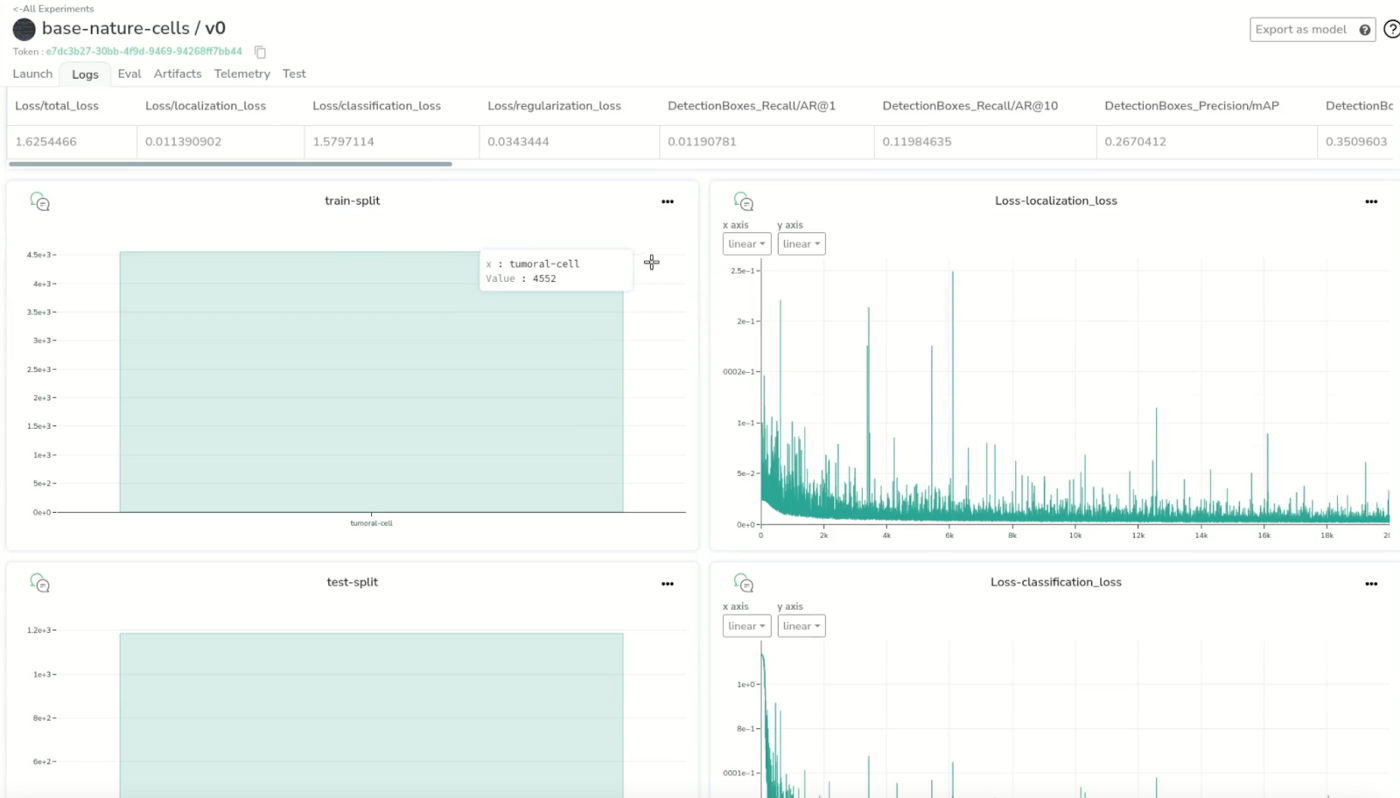
If we go back to the “logs” tab, we can see we already have some metrics such as train-split and the loss that is logged in real time during the training but has the activity history, which is the train/test split of the dataset and some epochs already for which we can check the loss in real time.
A few hours later, we want to check the “telemetry” tab. It took three hours for the experiments to finish.
Now we can see that our training is over and that everything has been logged correctly. We can even check thoroughly. In this case, we can observe that the evaluation and uploading of the artifacts went well.

Let’s get back to our dashboard to see all our training metrics. Now we have much more information. We have all the charts from the different loss curves, our evaluation metrics, and more. We can observe that our loss seems to have reached a minimum, and say that it is good enough to the effects of this demo.

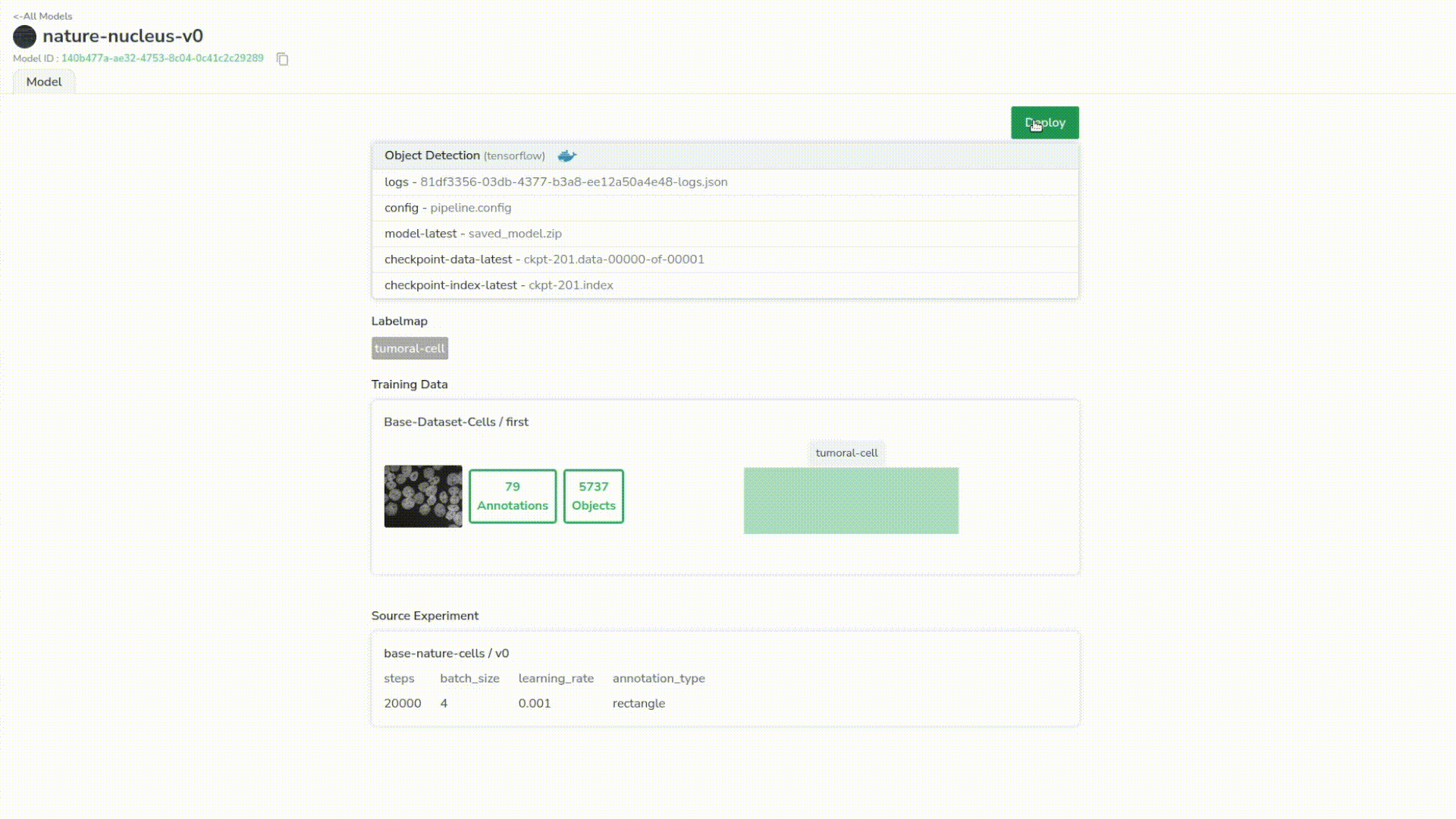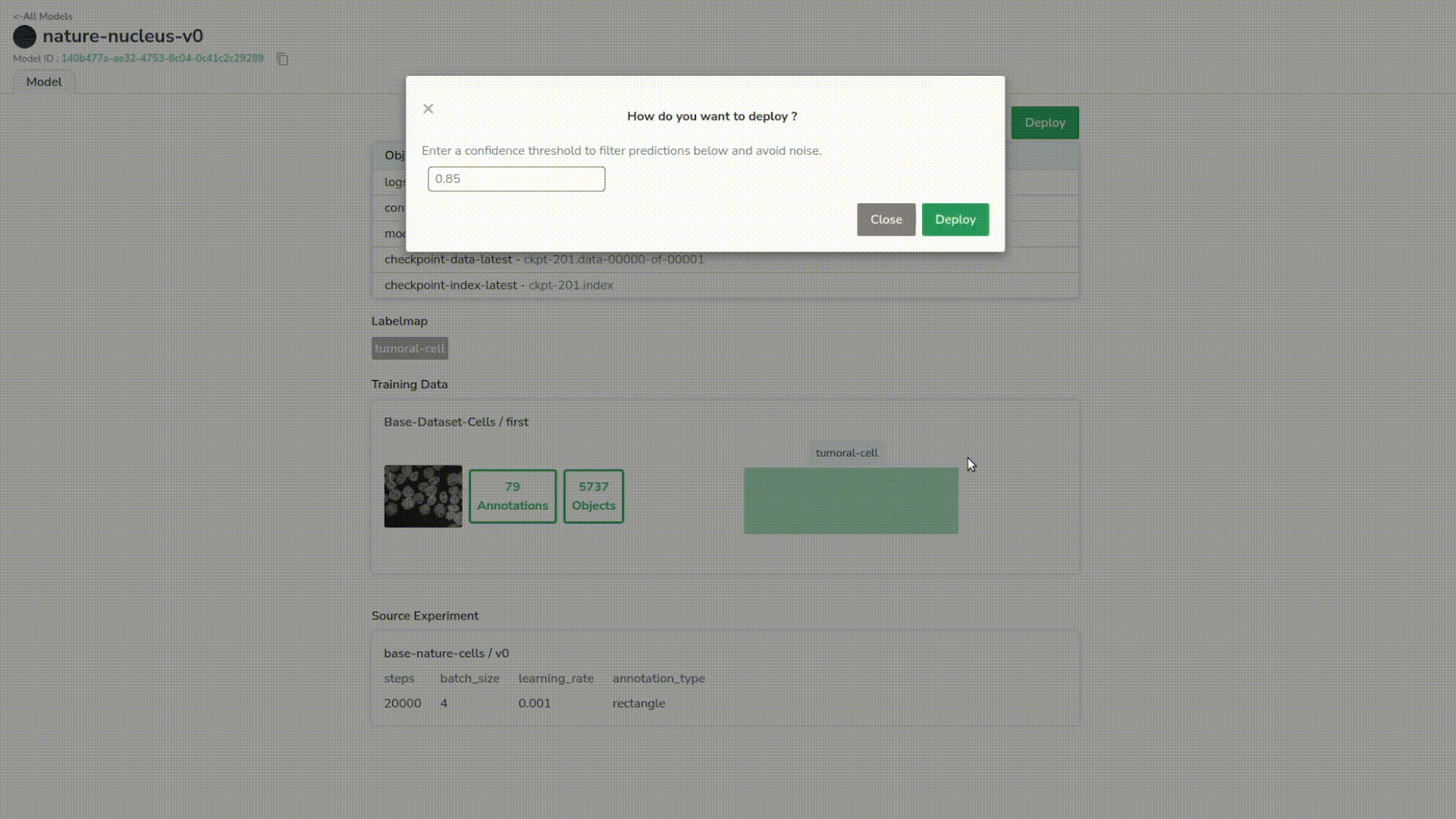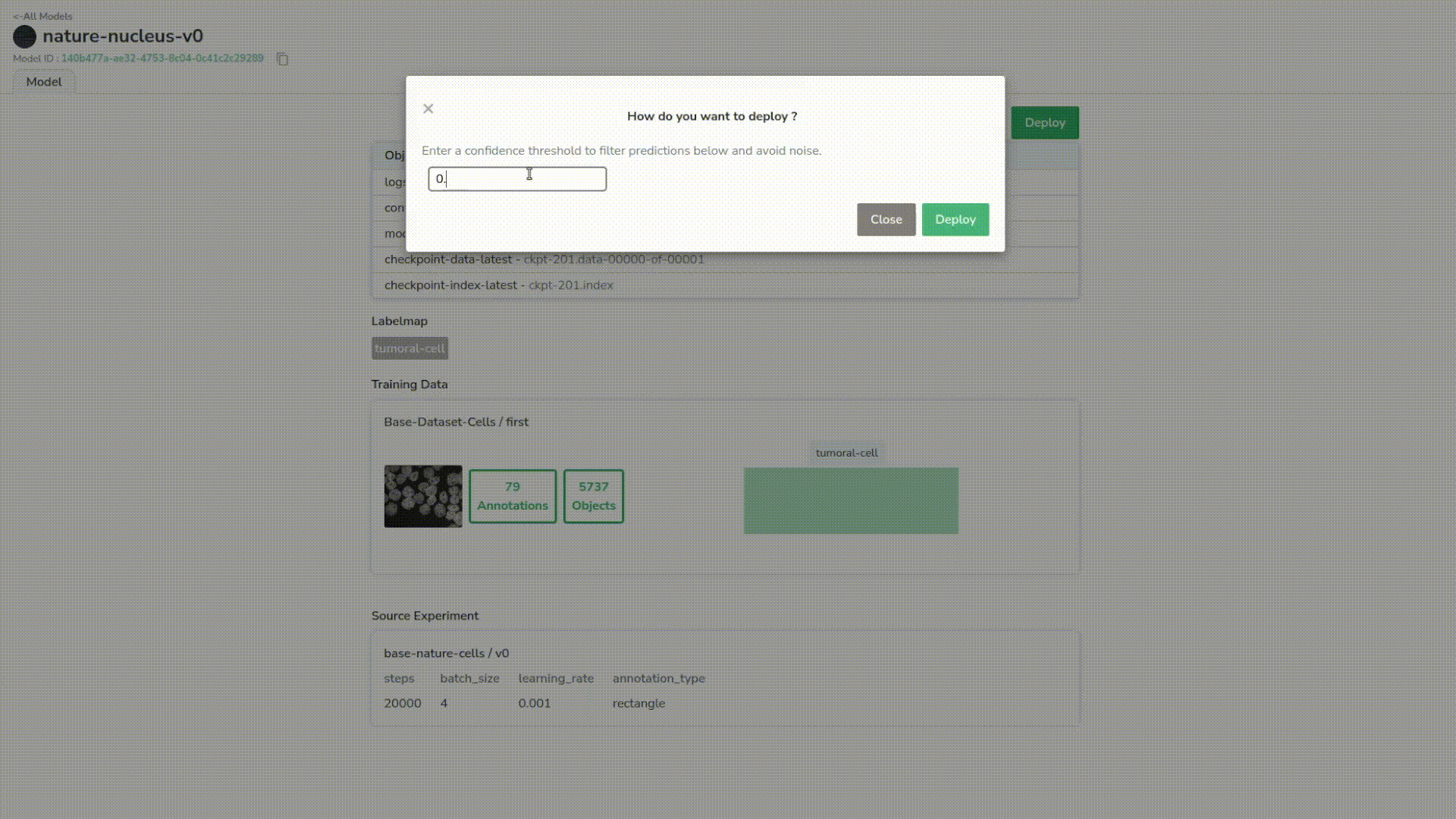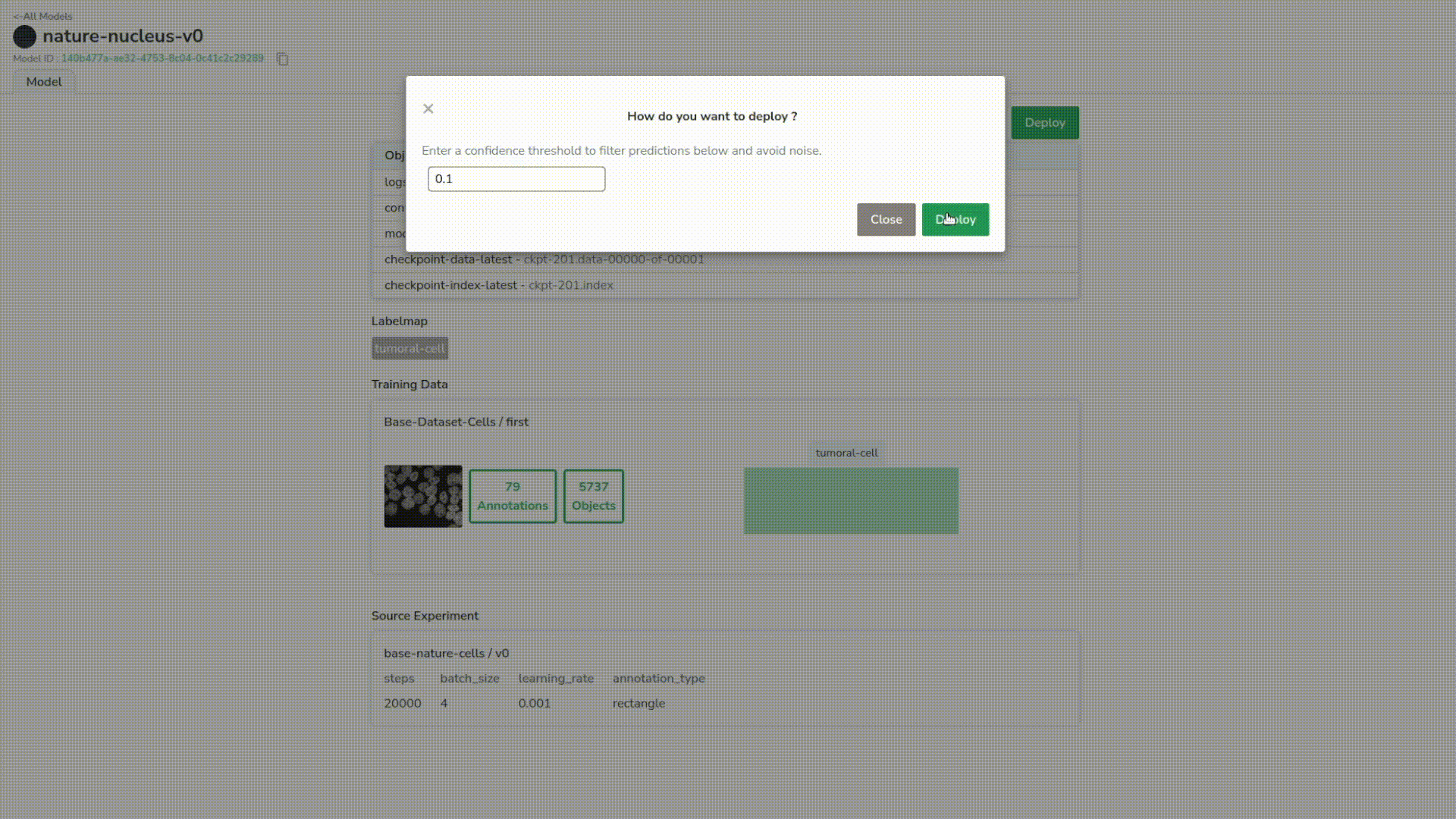
Exporting the model
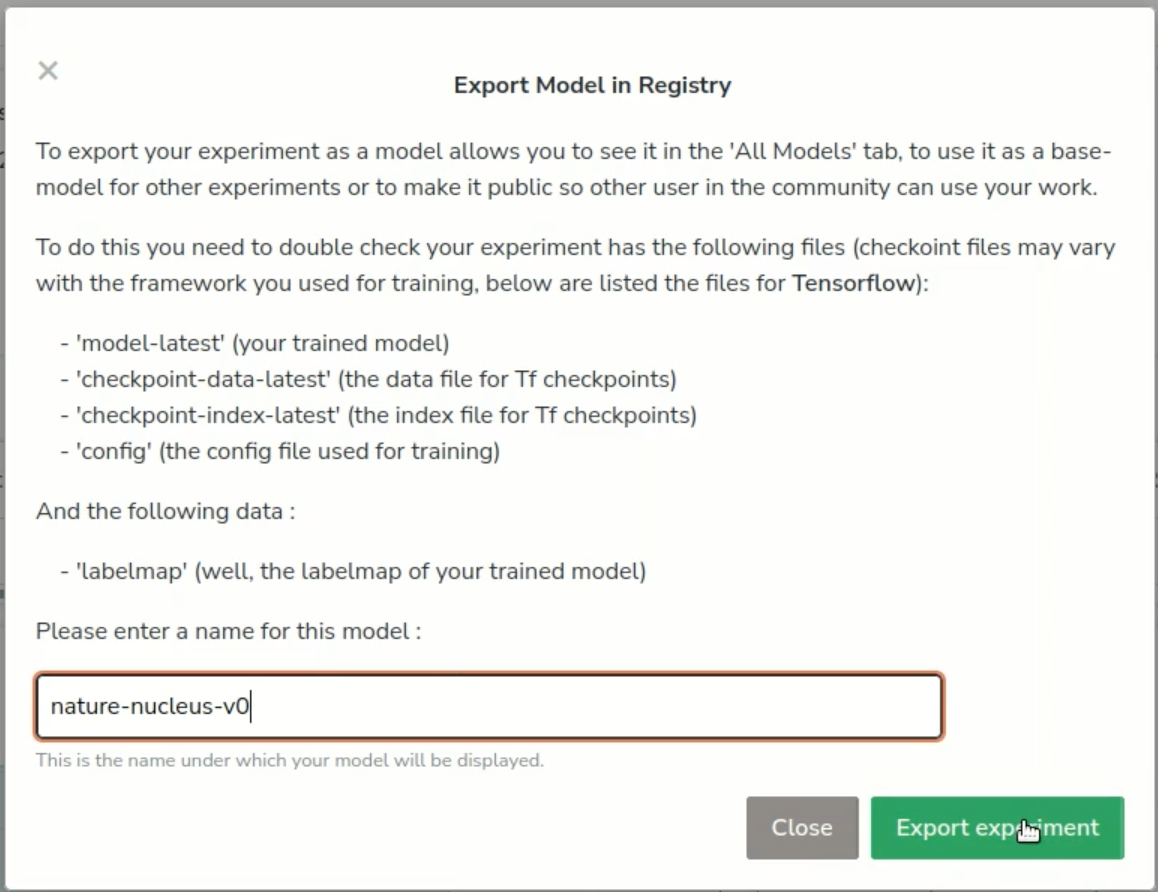
Next, we want to export the experiment (click the “export” button at the top right). In other words, we’ll convert the experiment into a model and save it in our registry, that we will be able to deploy.
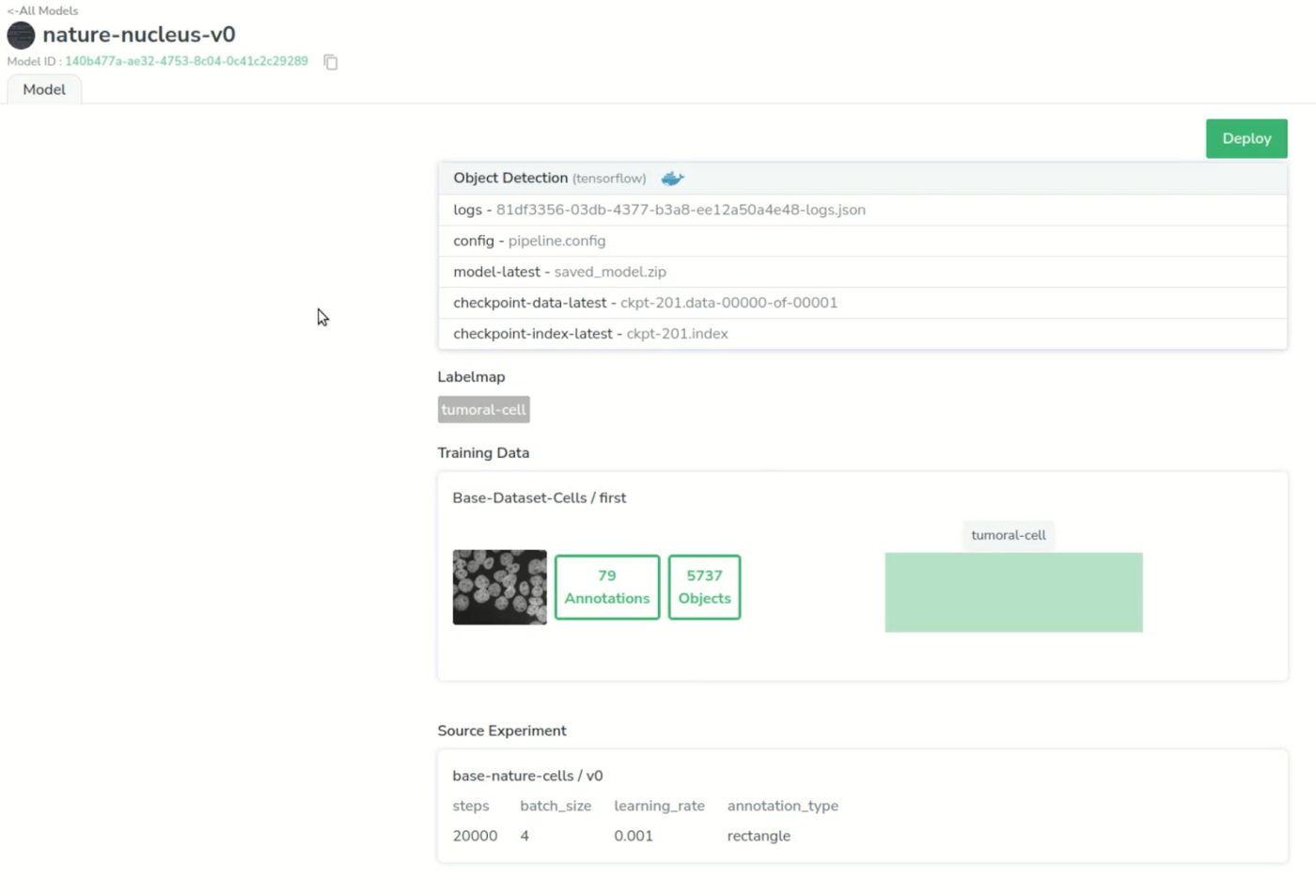
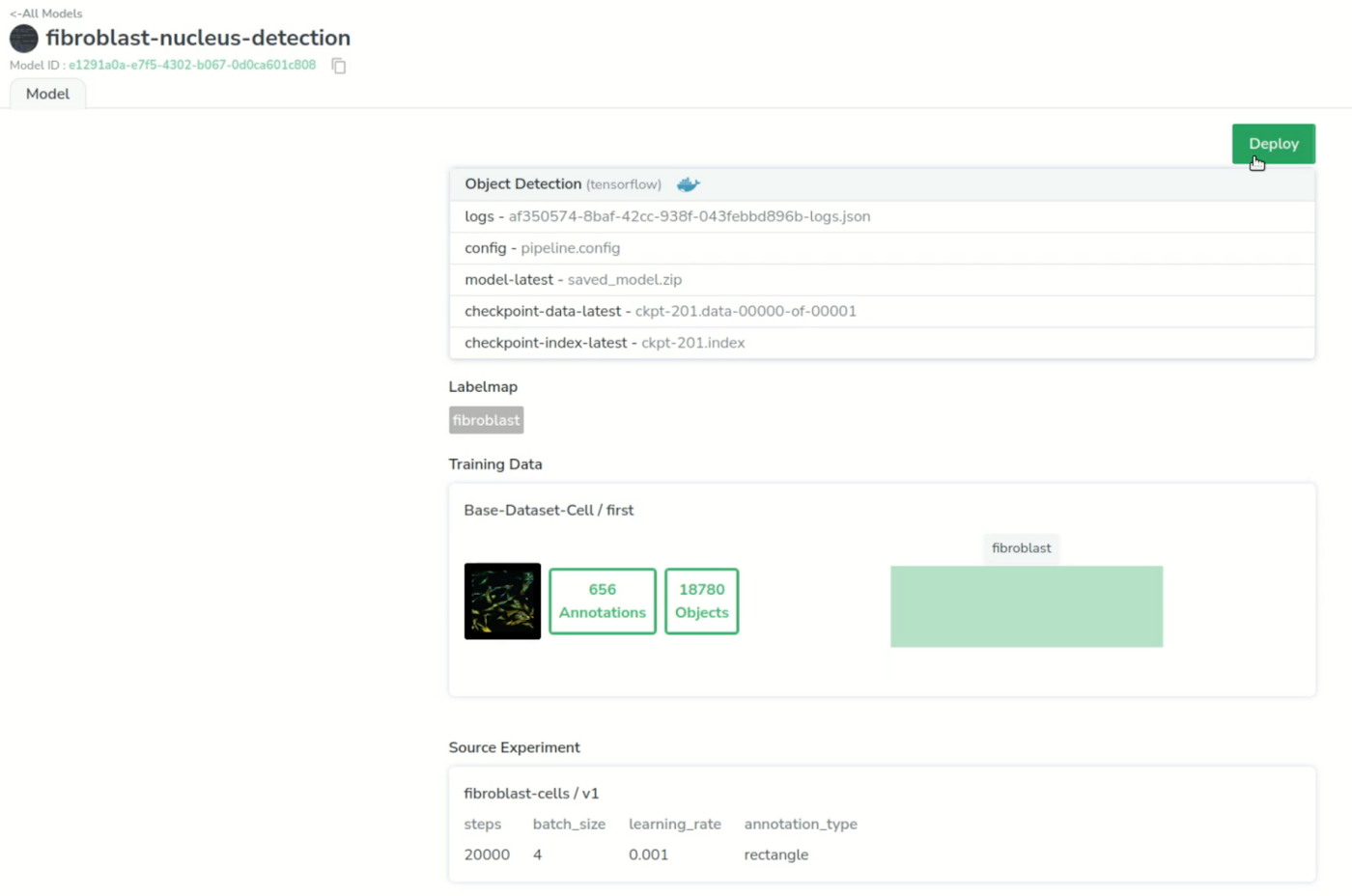
This leads us to our registry in the “model” page, where we can access the files it has to retrain or deploy, the label map, the training data and the original experiment.
Deploying the model
Next, click on “deploy” and set a minimum confidence threshold to limit noise in our predictions.
And we just created a deployed model!
Making predictions/inferences
Now we want to make some predictions with our model, for which we just have to copy the name of the deployment and head down to a notebook or anywhere you can make an API call.
We will use our Python SDK to call our deployment. With a simple method we will authenticate and retrieve the deployment information. Then we’ll have to select a folder with images we want to perform predictions on, and send them to the model with the predict method.
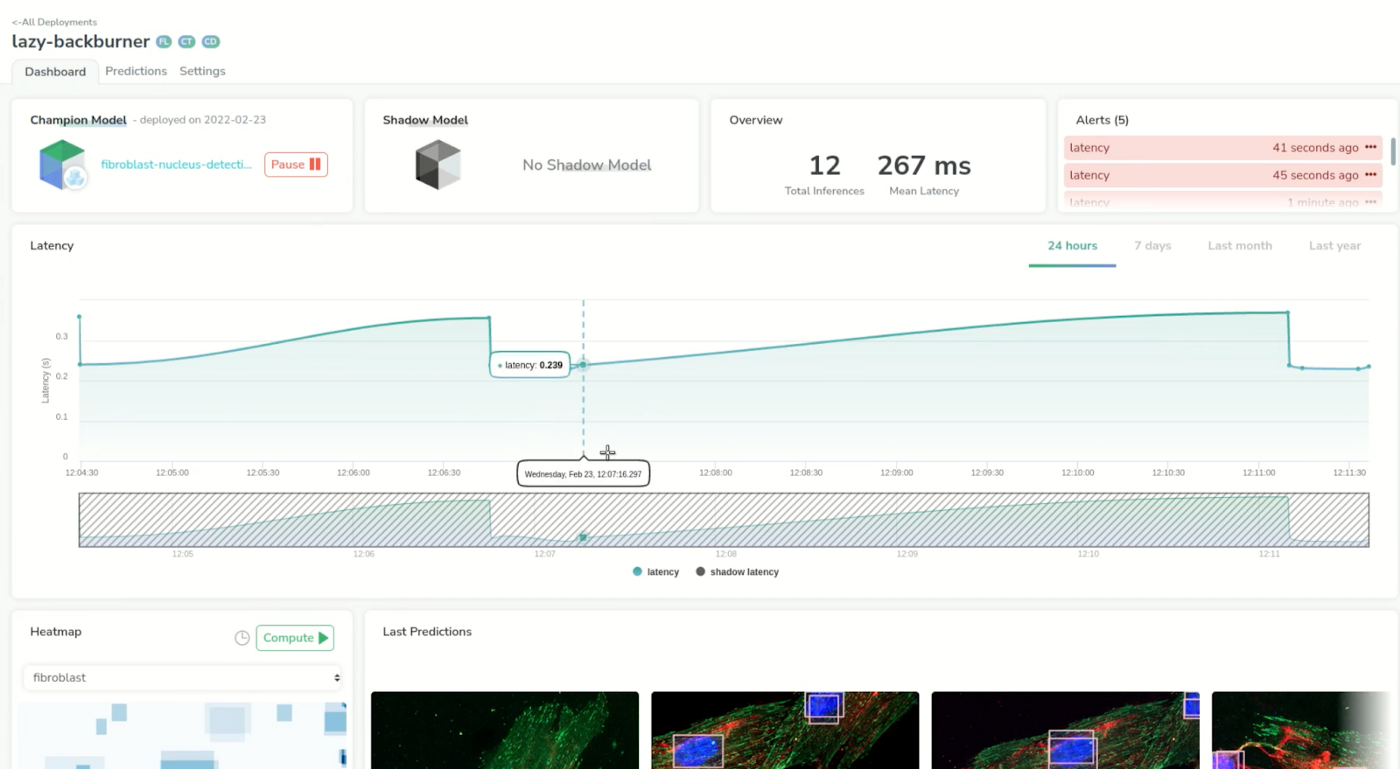
A great thing about Picsellia is that we can see predictions live in the dashboard. We have some simple but critical information such as the latency of the model.
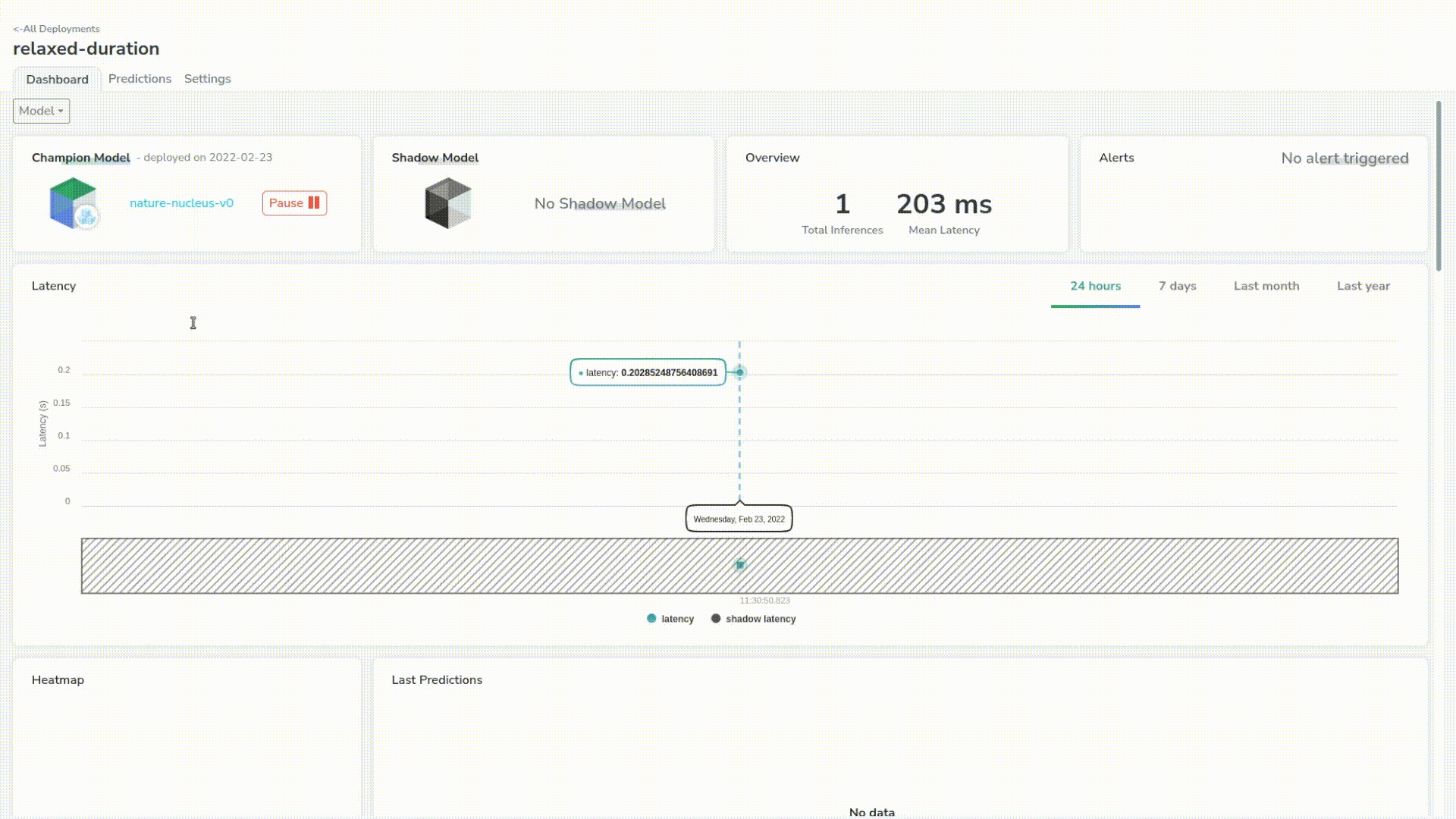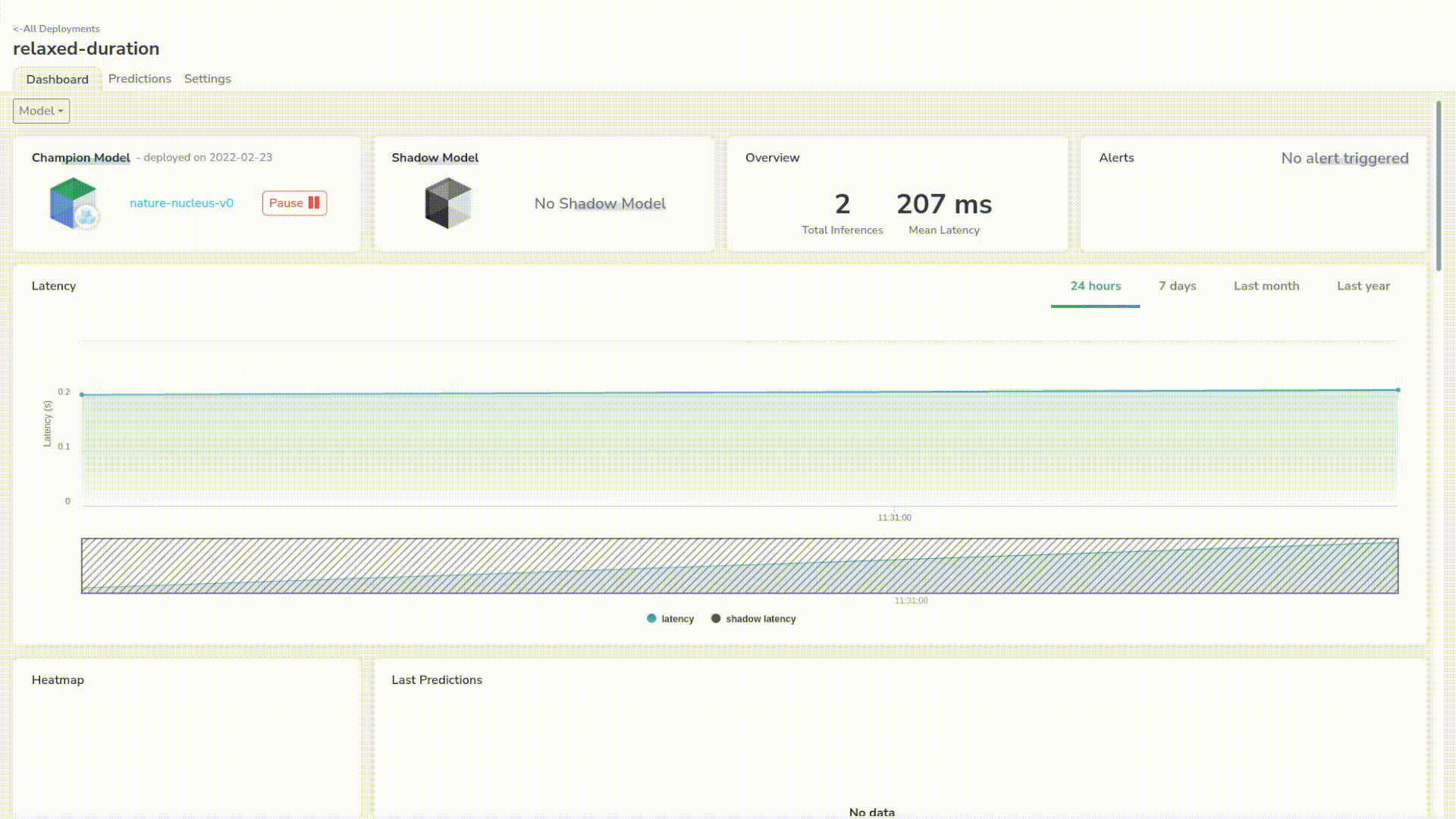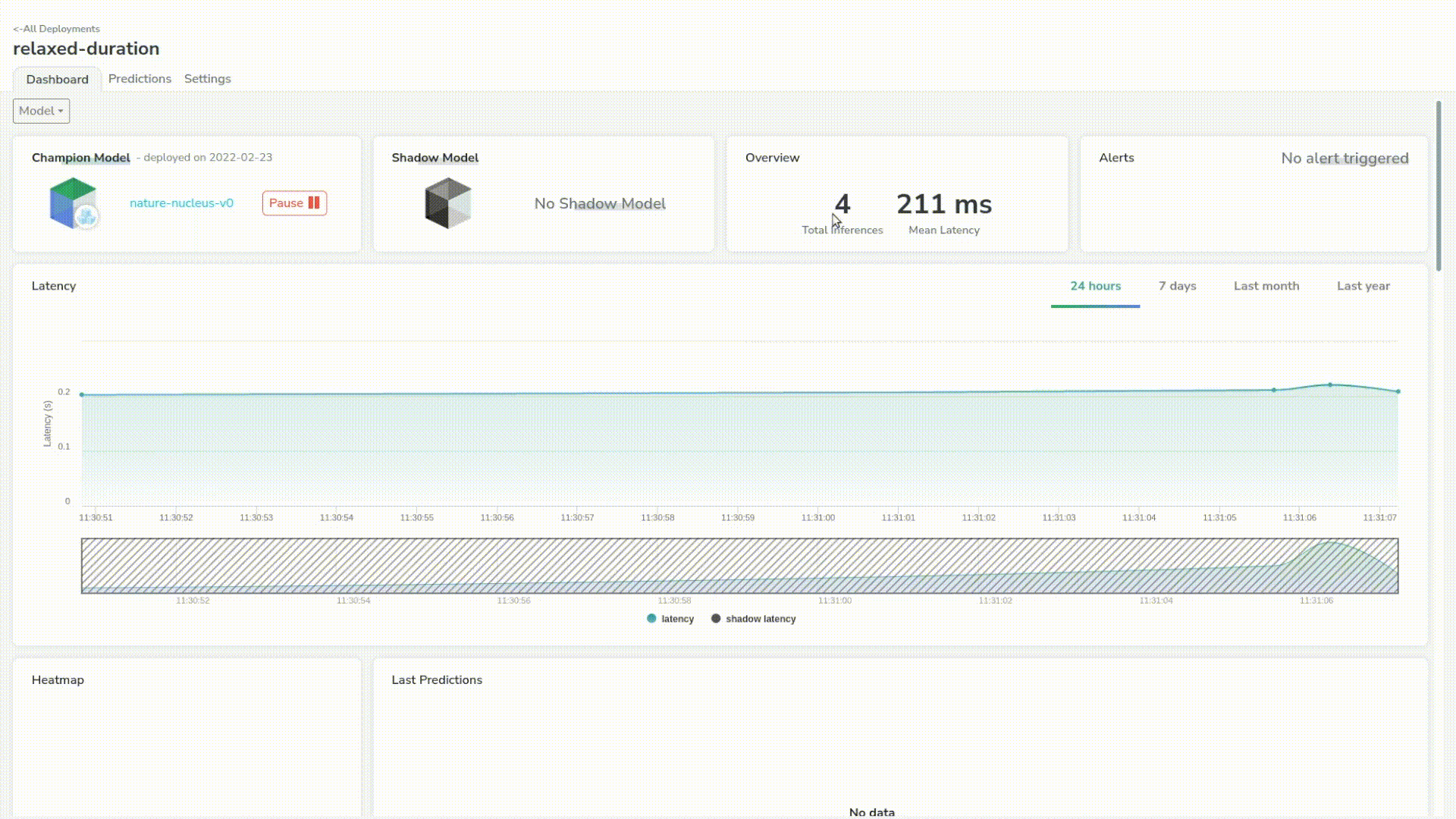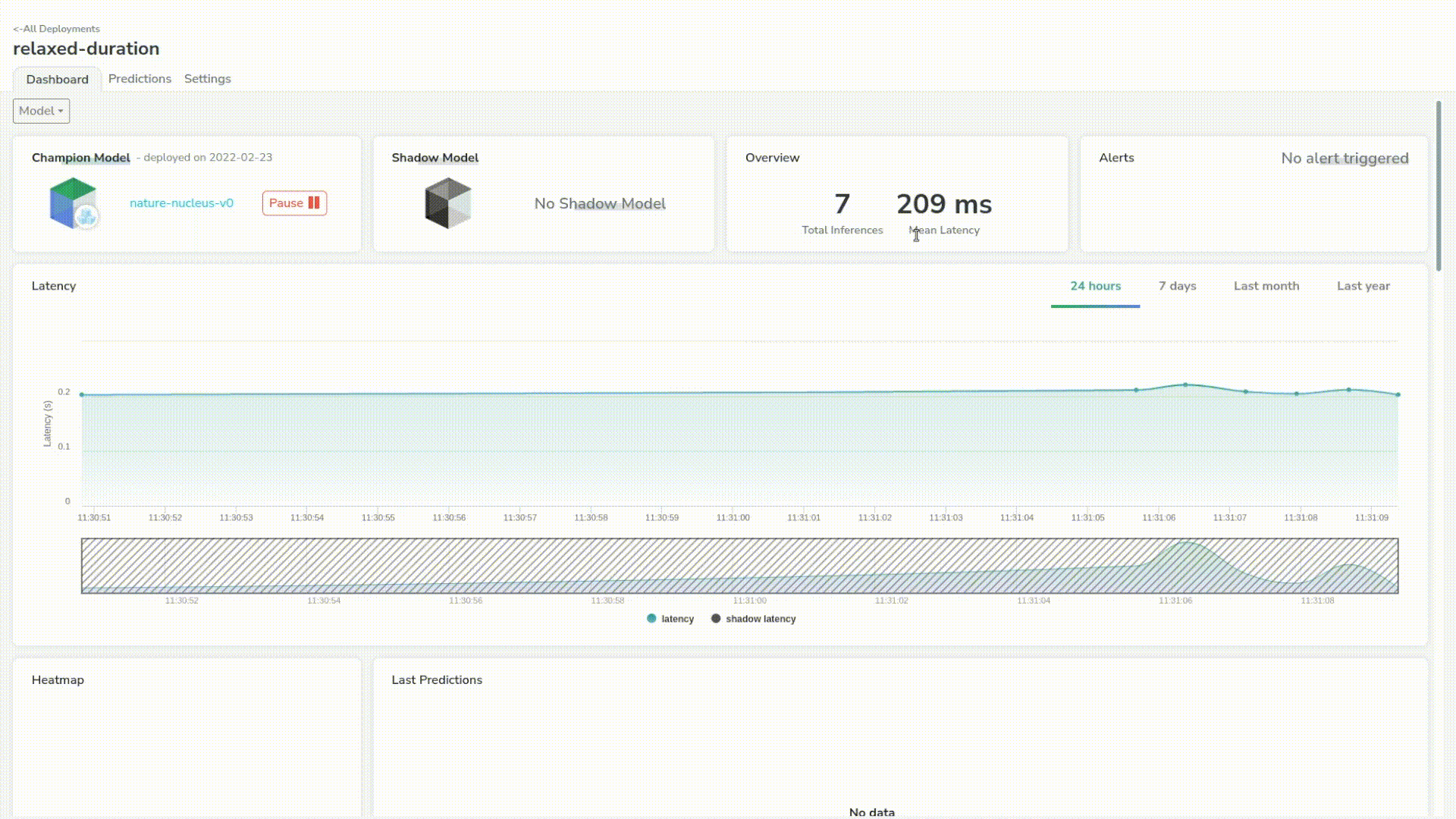
Let’s send a few more just to trace a better chart. We can see that our model has a mean latency of 210ms which is pretty good for a first step.

If we go to the “predictions” tab, we can now see all the predictions made by our model, (it should remind you of the Dataset tab).

As we can see, our model is detecting our cells but there is still a lot of noise in the predictions, so we’ll have to clean this for retraining another model.
Before reviewing, we will set up what we call the ‘feedback loop’ in our deployment settings, which sets a target dataset where our reviewed predictions will land.
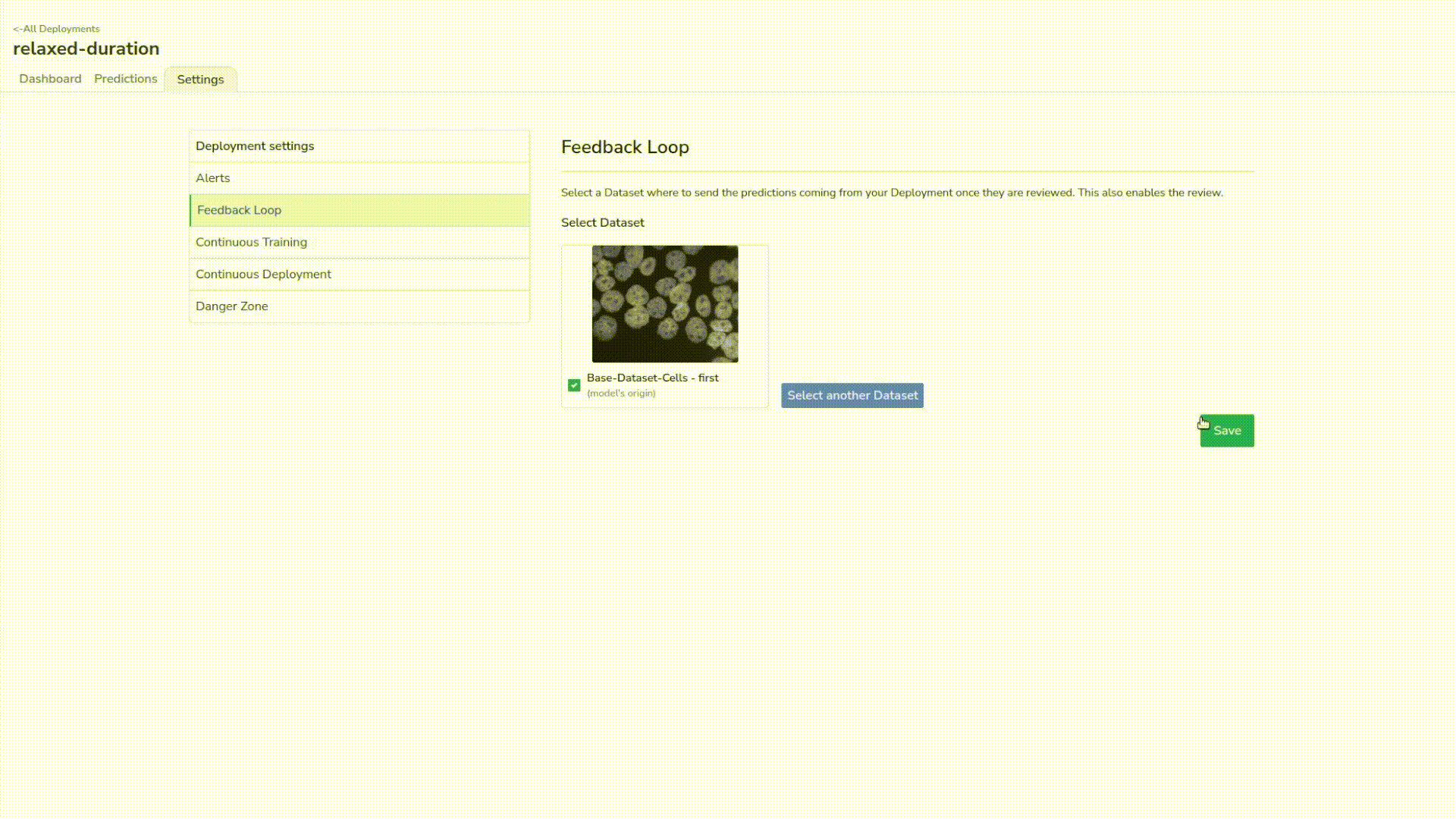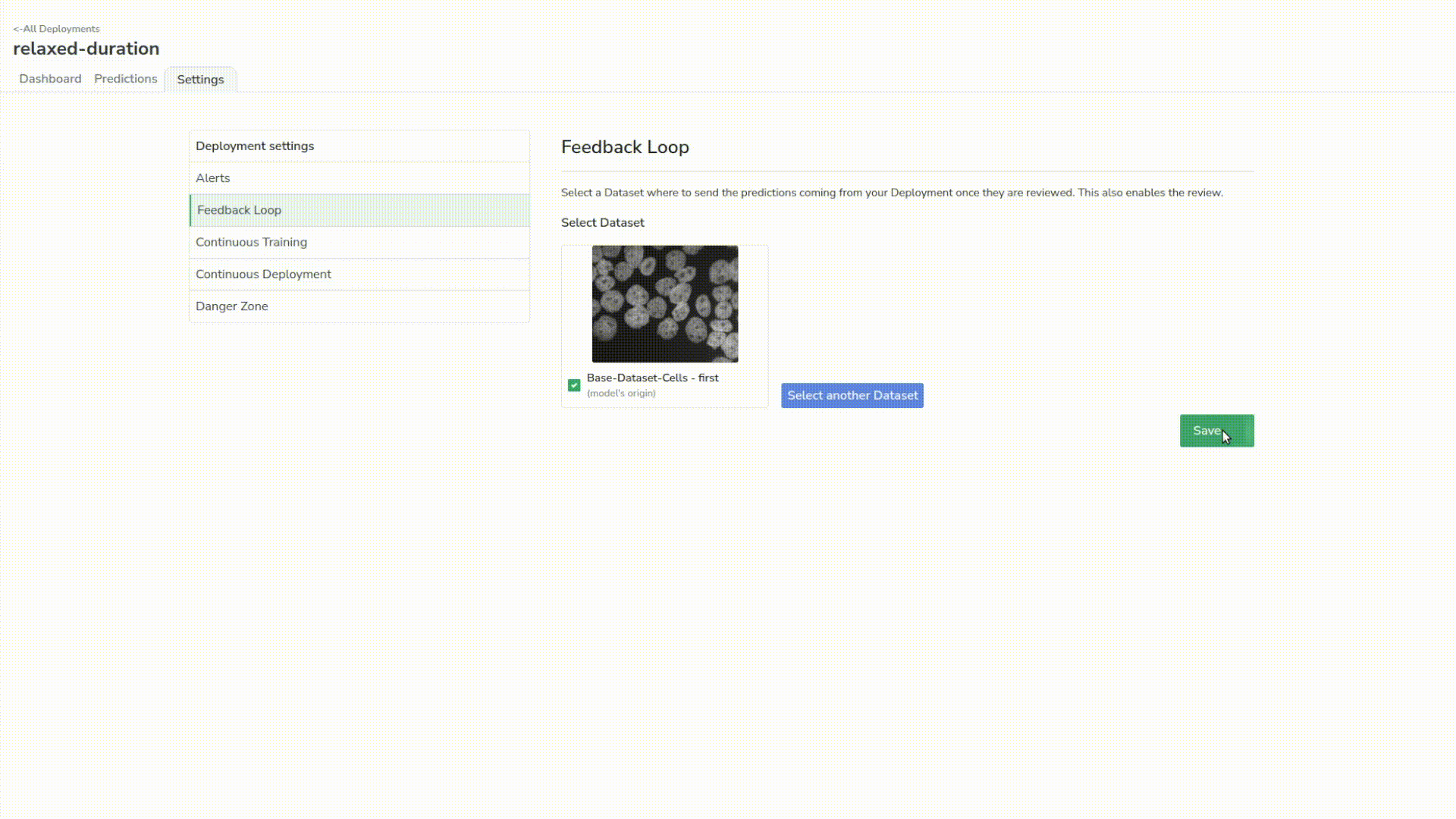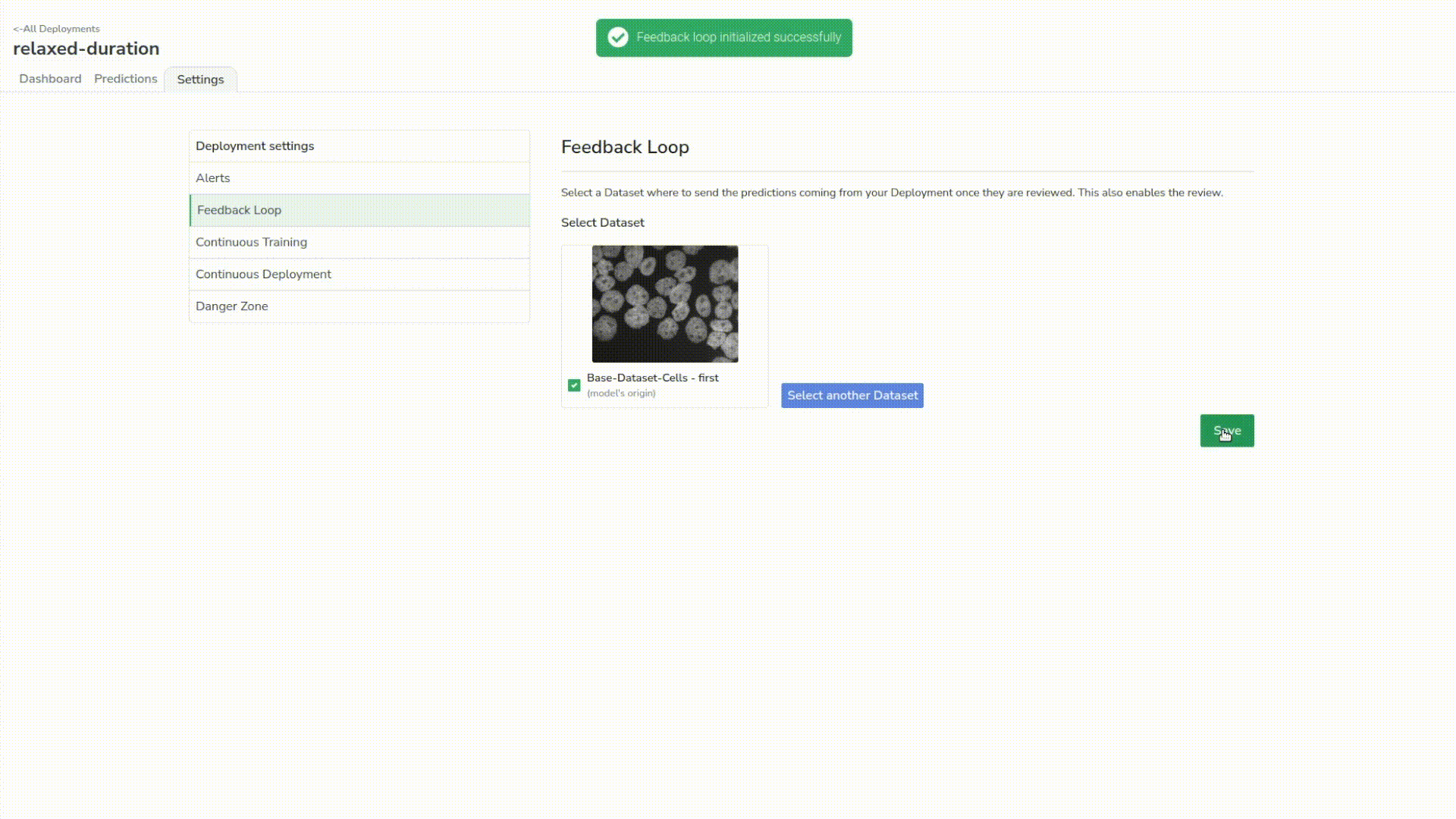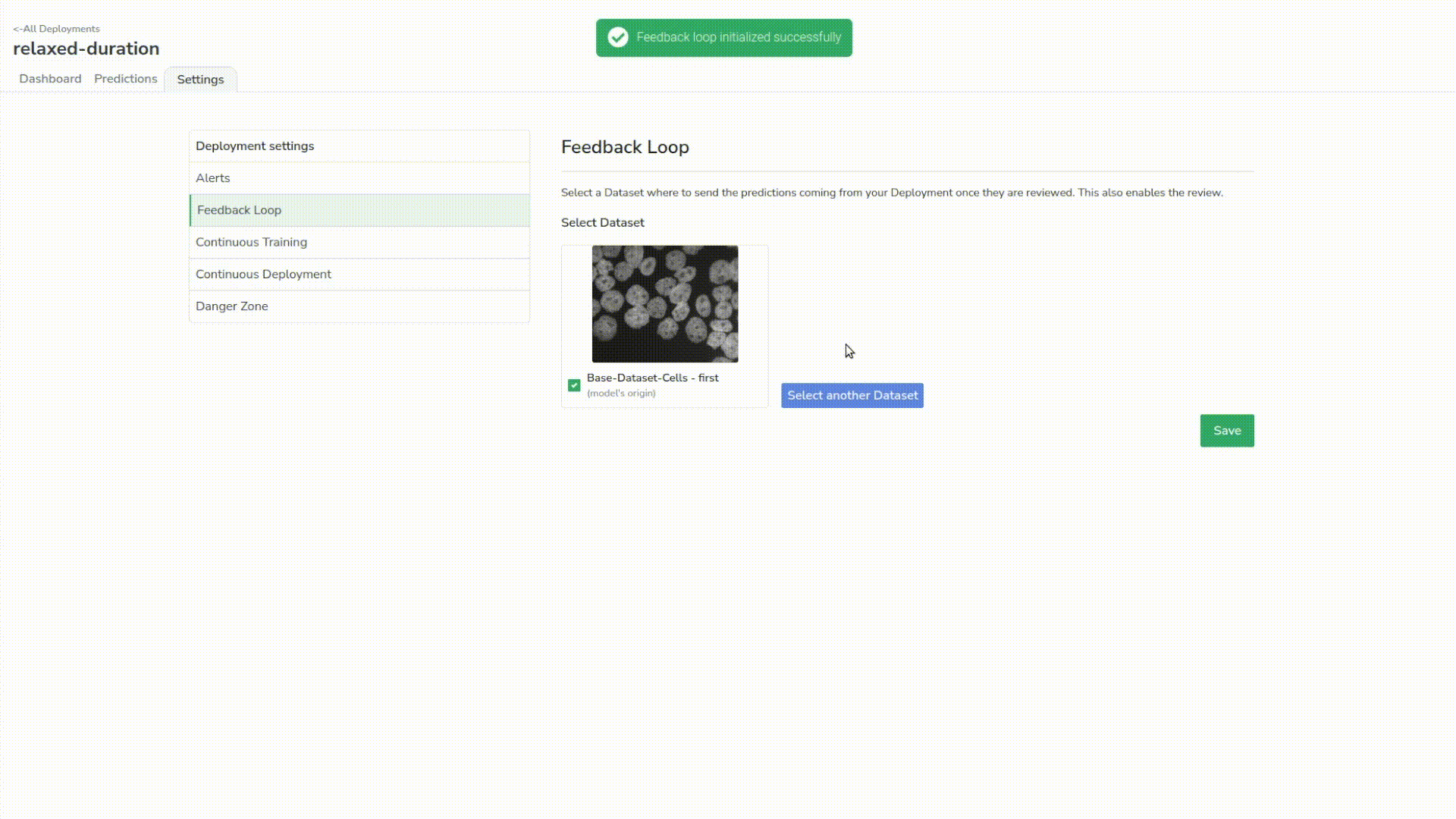
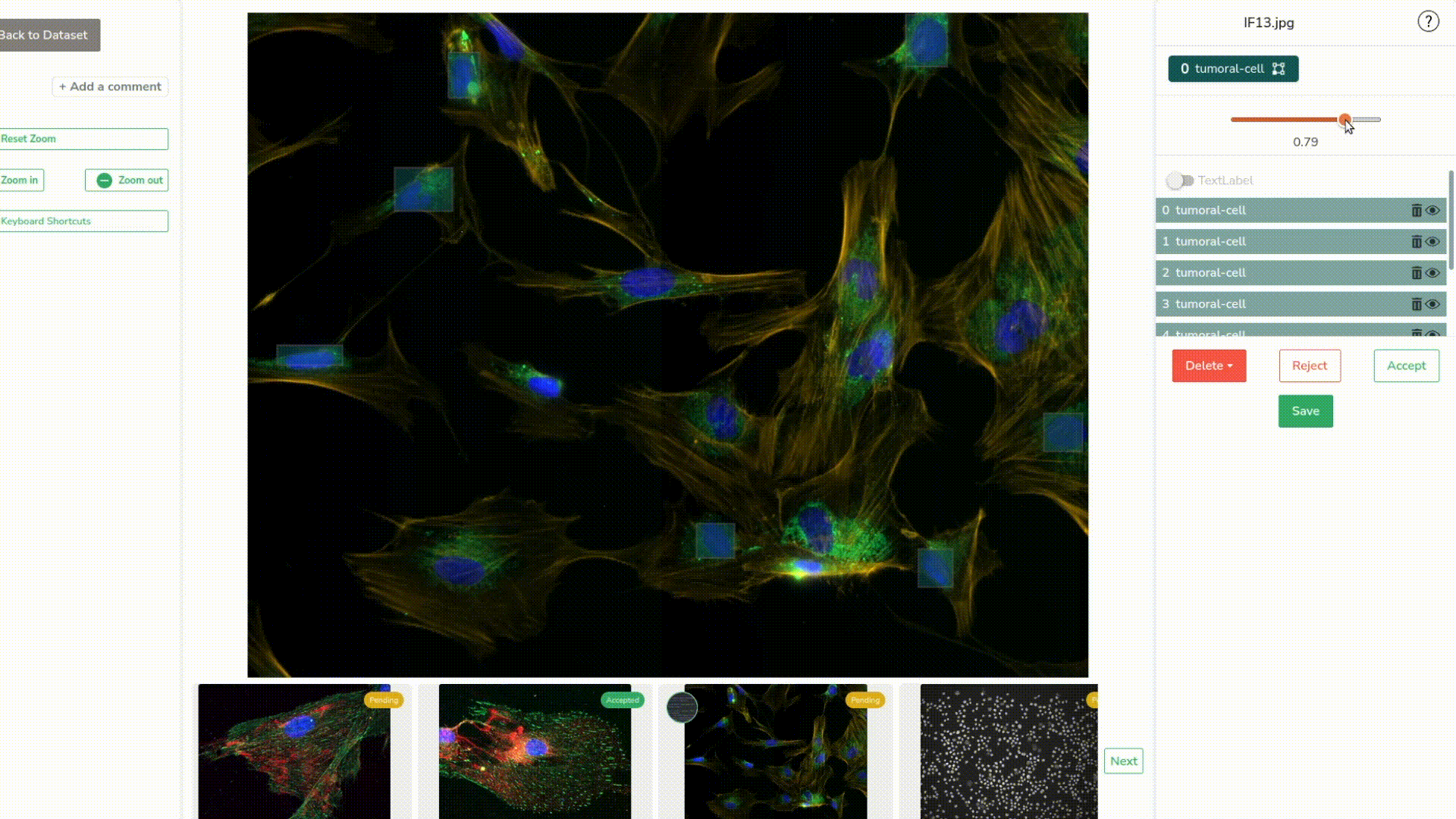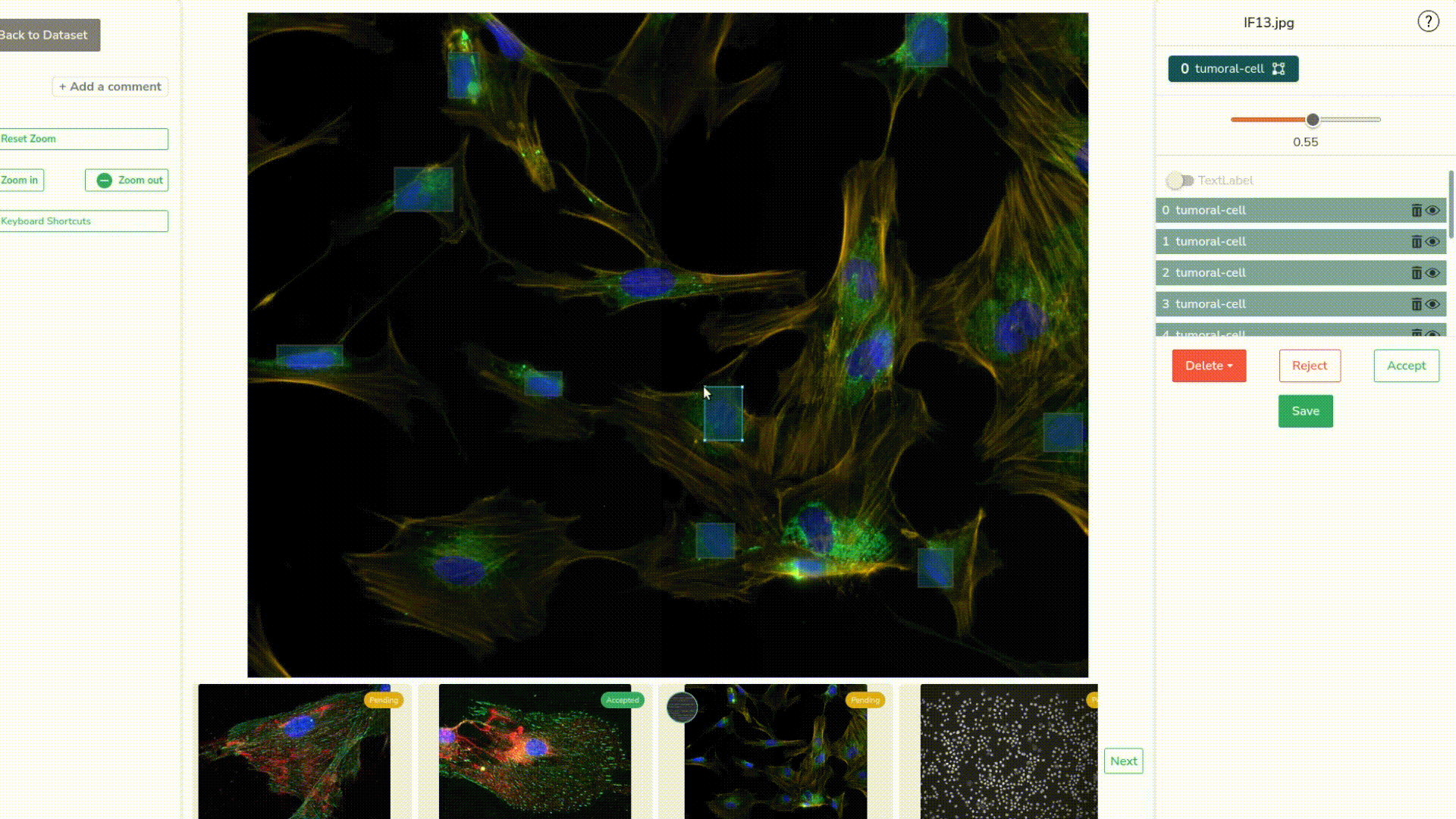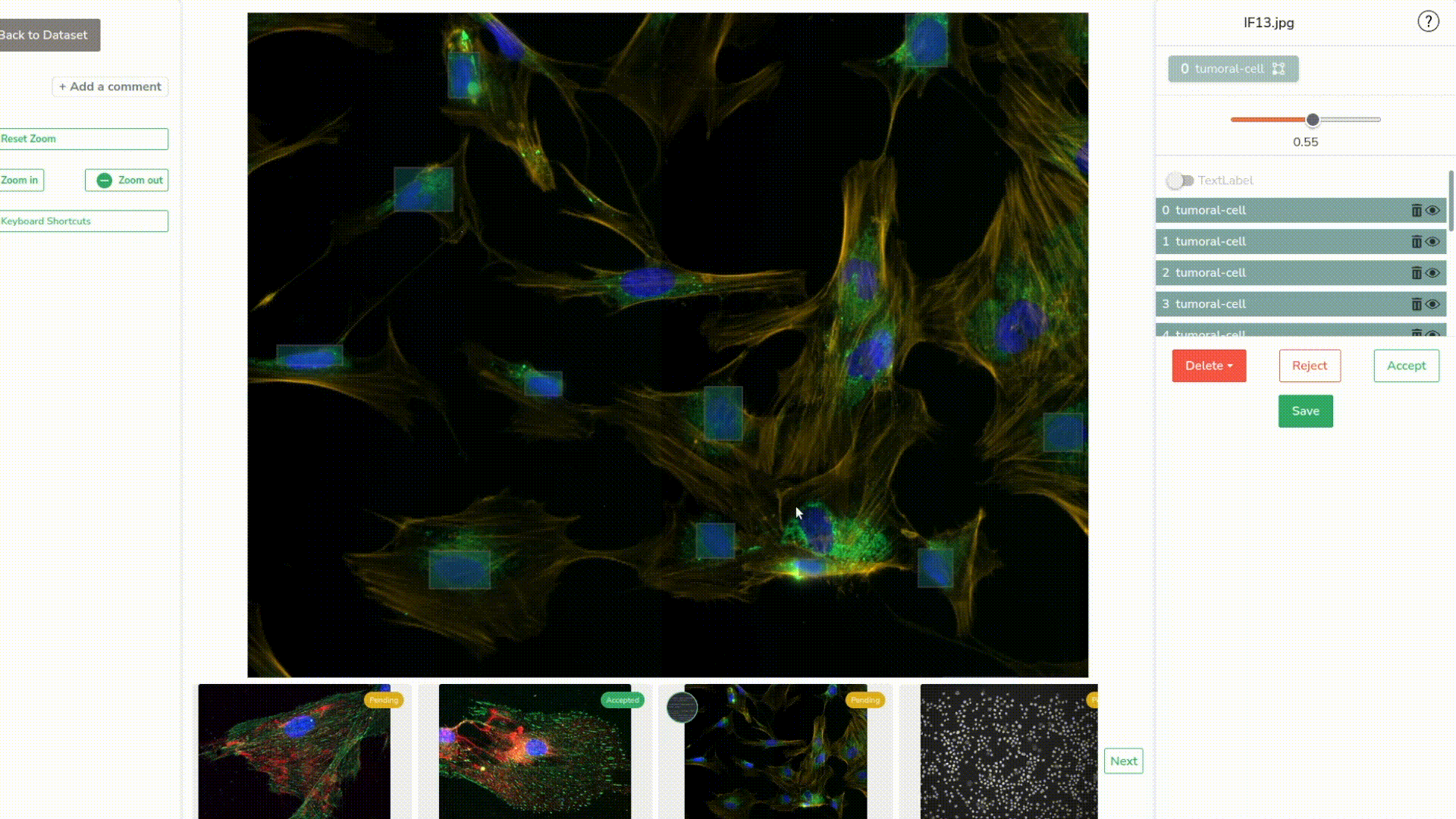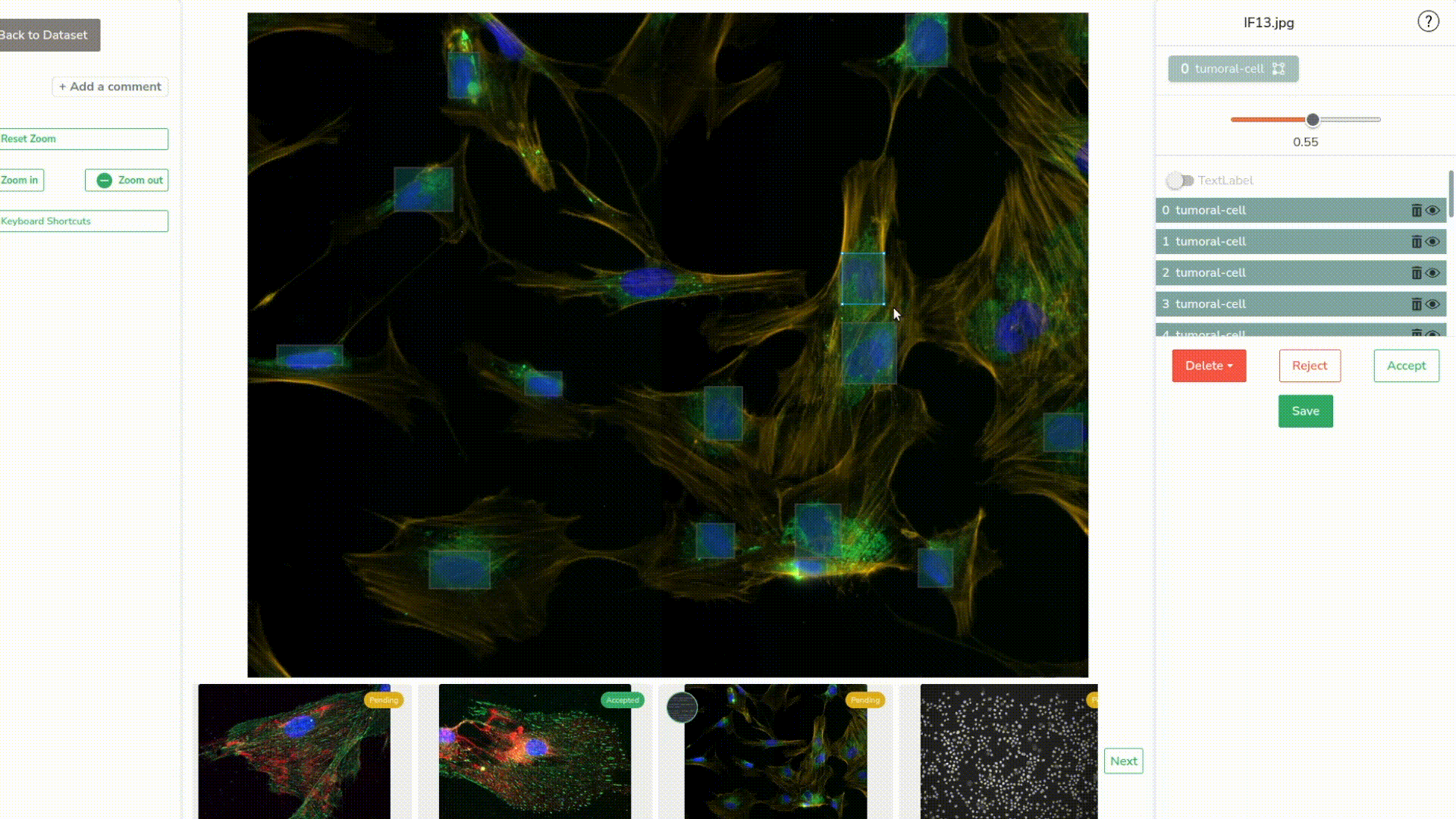
Now we can review our predictions. It’s basically the same process as labeling your data the first time, except that you can filter the predictions by confidence threshold and then edit the objects to make the annotations as neat and fast as possible.
If we go back to our dashboard, we will now have access to some more interesting metrics to ensure the quality of the model’s predictions. You will find pure object detection metrics such as average recall, average precision, the global and per prediction label distribution, information about image distribution and also automated data drift detection.
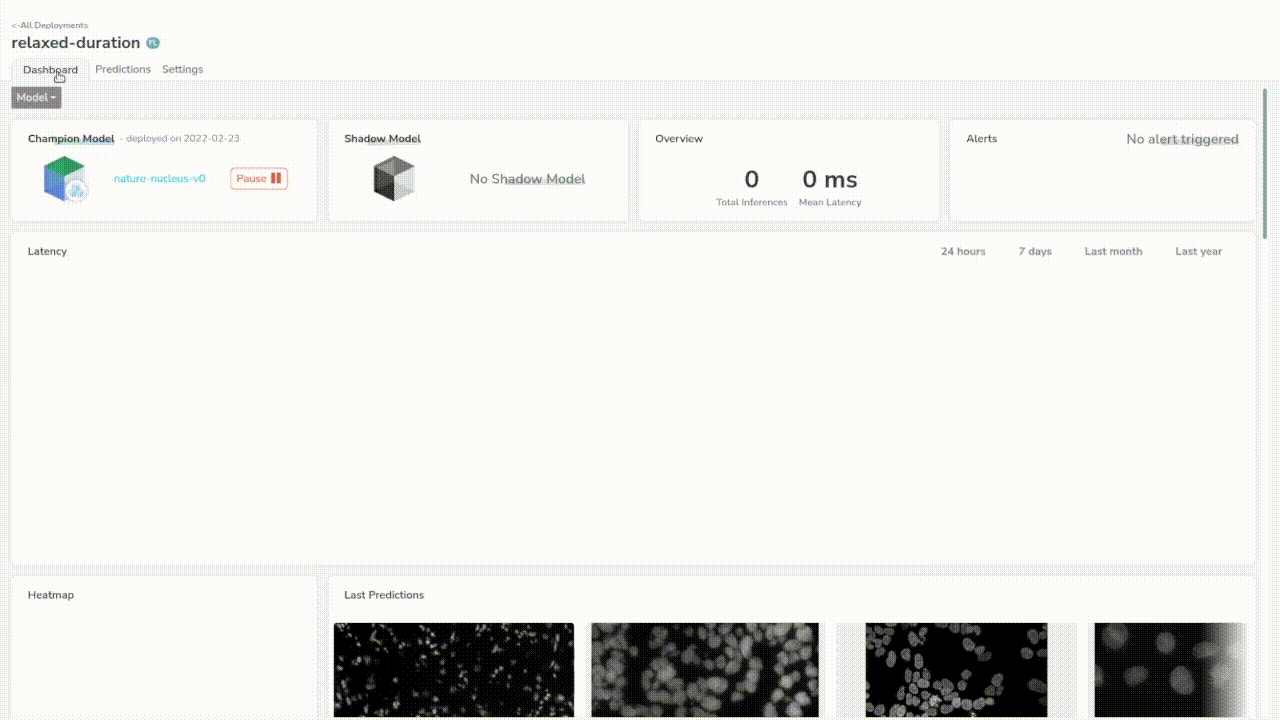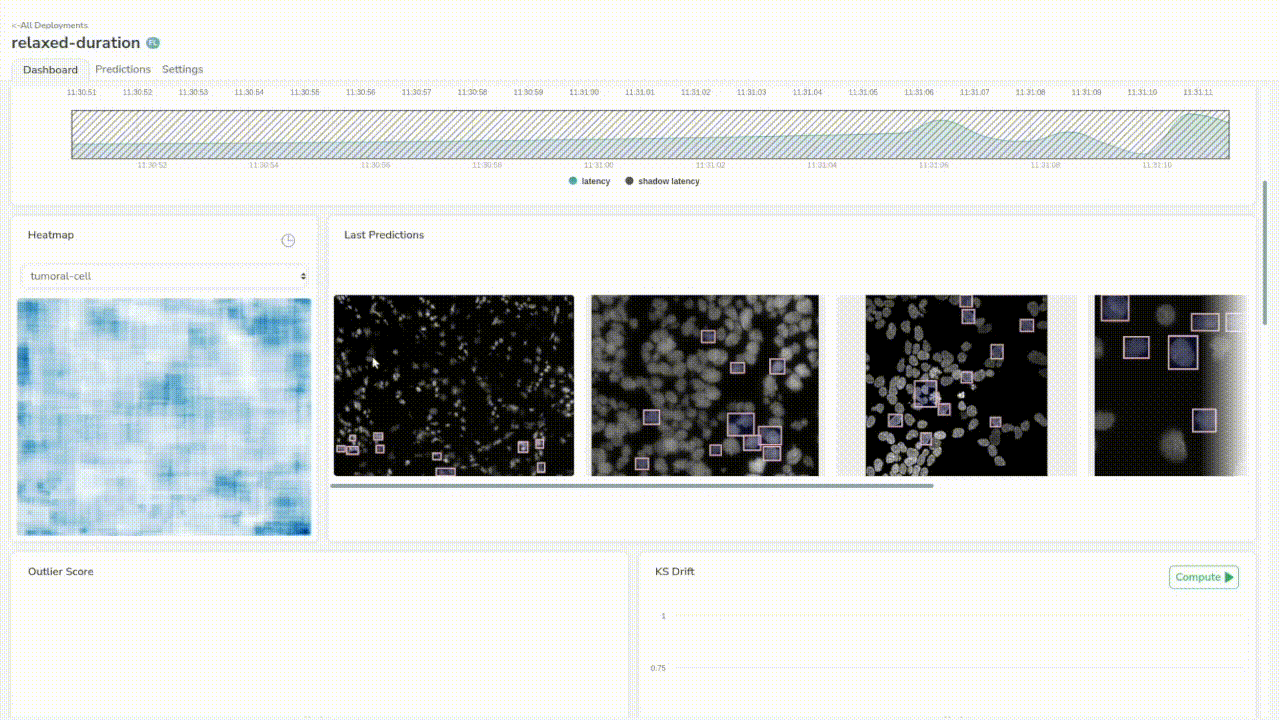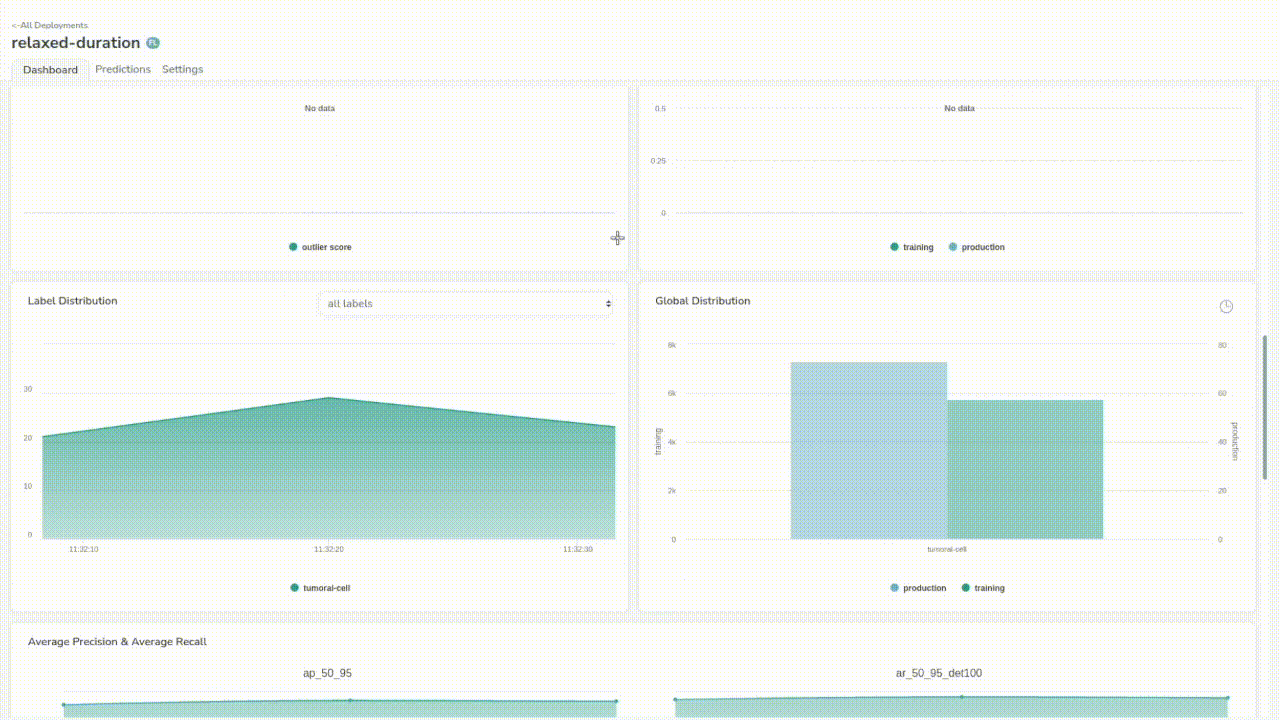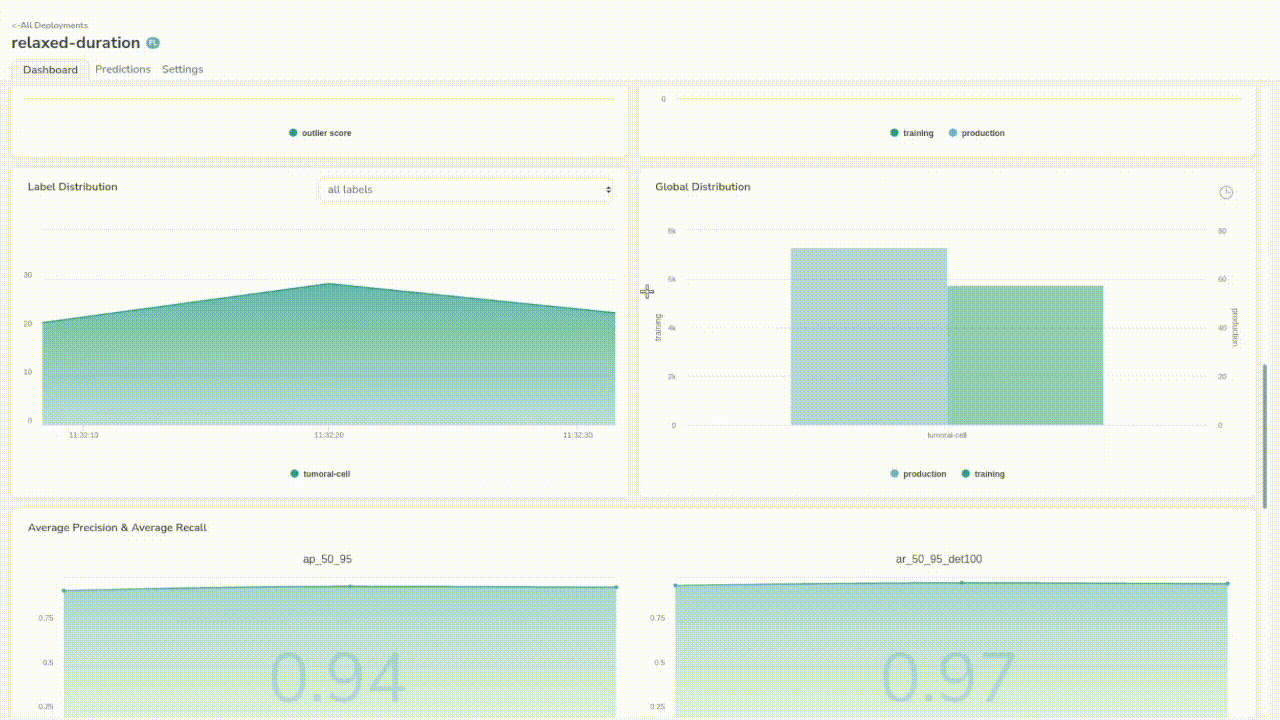
Now, we have a base model that makes somewhat alright predictions, but our final goal is to train a model that will perform well on our custom dataset.
Training a model on a custom dataset of fibroblast nucleus
The process will consist of sending all the images through our model, which will do some pre-annotations, and then refine them to create a clean dataset to retrain a new model suited for our use-case.
Let’s predict our images. We can see that it did detect some of our nucleuses. Let’s go check those predictions closer.
Once again, we review and edit the new predictions the best we can–it is often pretty easy thanks to the threshold slider.
As you might remember, earlier, we set up in the settings of our deployment, what we call a feedback loop. This means that now that we’ve sent all our pictures through the model and reviewed them, they will all appear here and serve as training data.
We can see that the dataset consists of 30 images and has 712 objects annotated, which isn’t enough to train an object detection model.
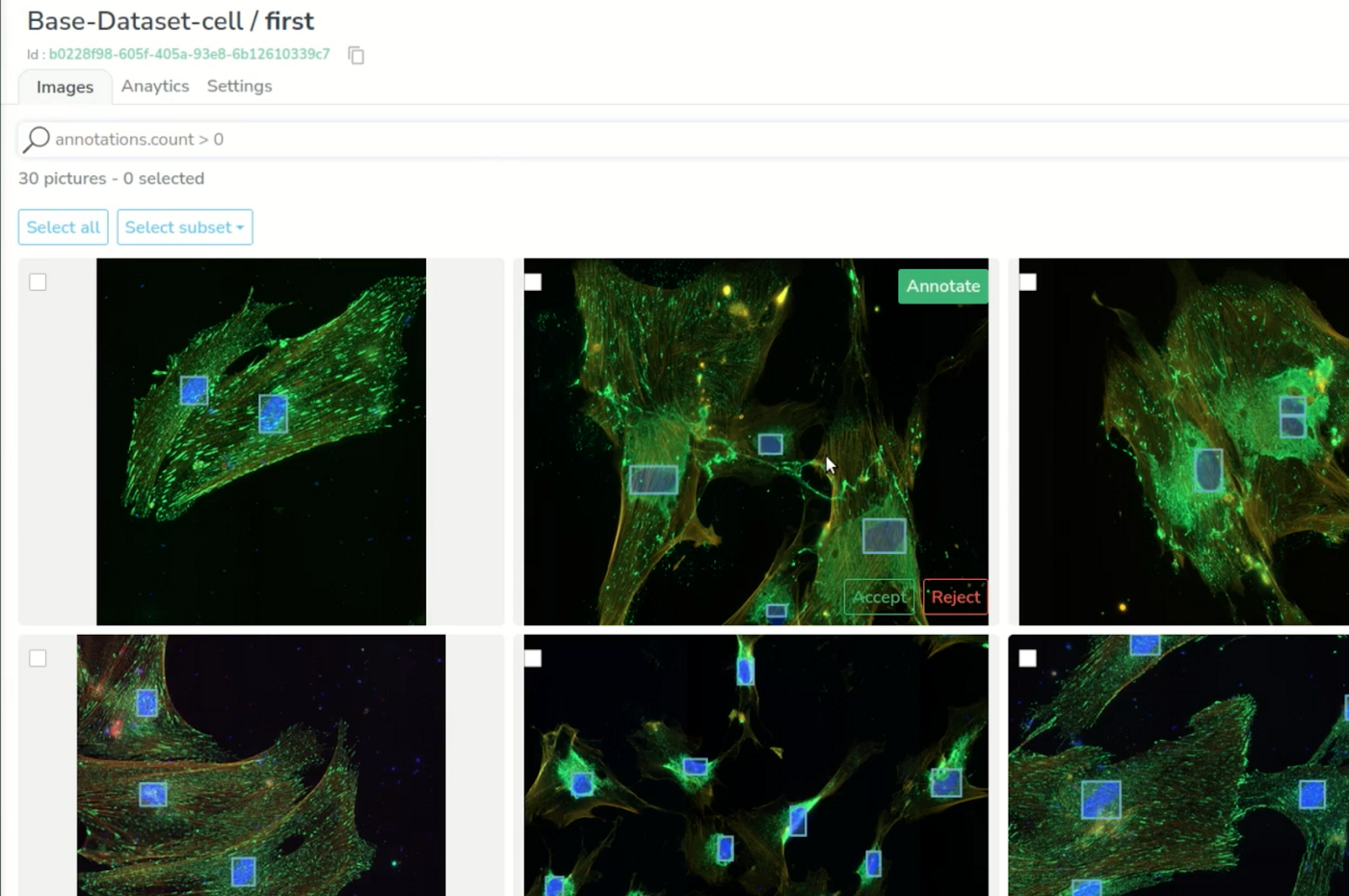
To enhance it, we will do some data augmentation with a script we prepared on the side, using some classic image manipulation, which leads us to this version of the dataset. The images have been randomly cropped, zoomed and rotated in order to create new samples easily. The dimensions look better now as we have nearly 700 images and 18000 objects.
Now that we have our dataset, we will follow the same process as our first training. We’ll create a project and attach our augmented dataset.
And again, create an experiment that will handle the training part. For it, we will choose the same base model as earlier and create our experiment. Just to be clear, we didn’t want to use our pre-trained model from the base cells to train this one. The goal here was to use the first trained model to pre-annotate the data to help us go faster to the second iteration. That’s not what we did here–and that’s why we’re still using an efficientdet_d2 architecture to train. But, another strategy would have been to use this model as the base architecture for our experiment.

Once again, we’ll launch it remotely.
Let’s check that our training runs correctly!

We return to our project dashboard a couple of hours later, and we can see successful experiments. We have two because we were not satisfied with the performance of the first one.
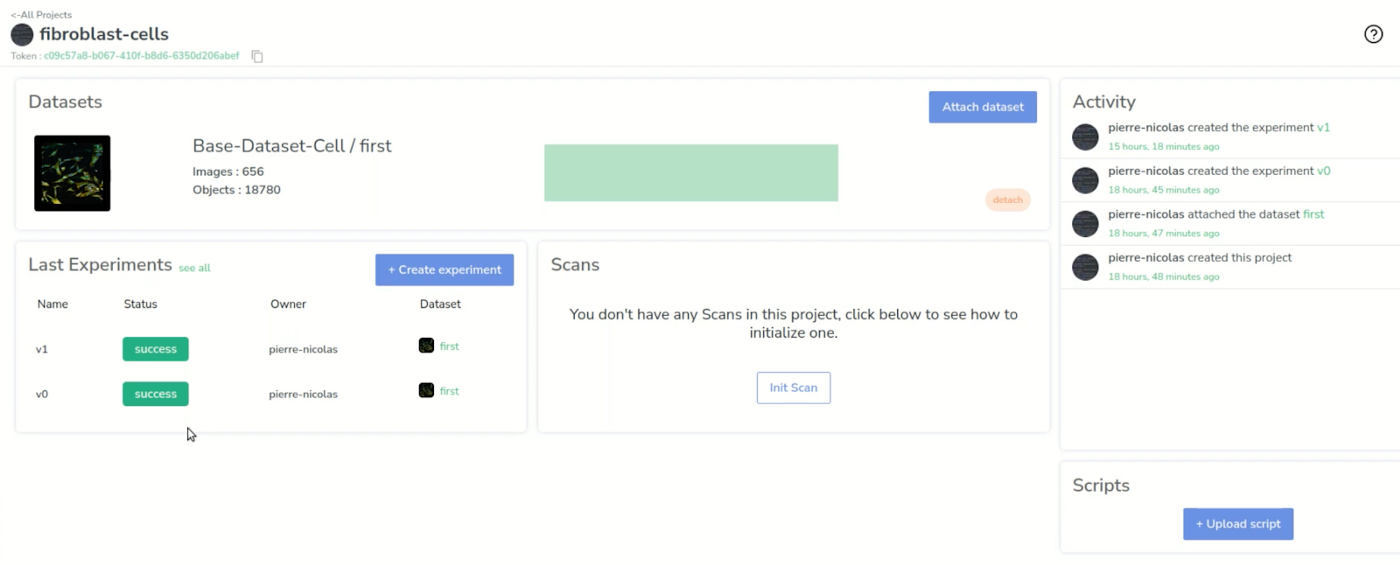
Let’s take a look at the server logs to check that nothing went wrong.
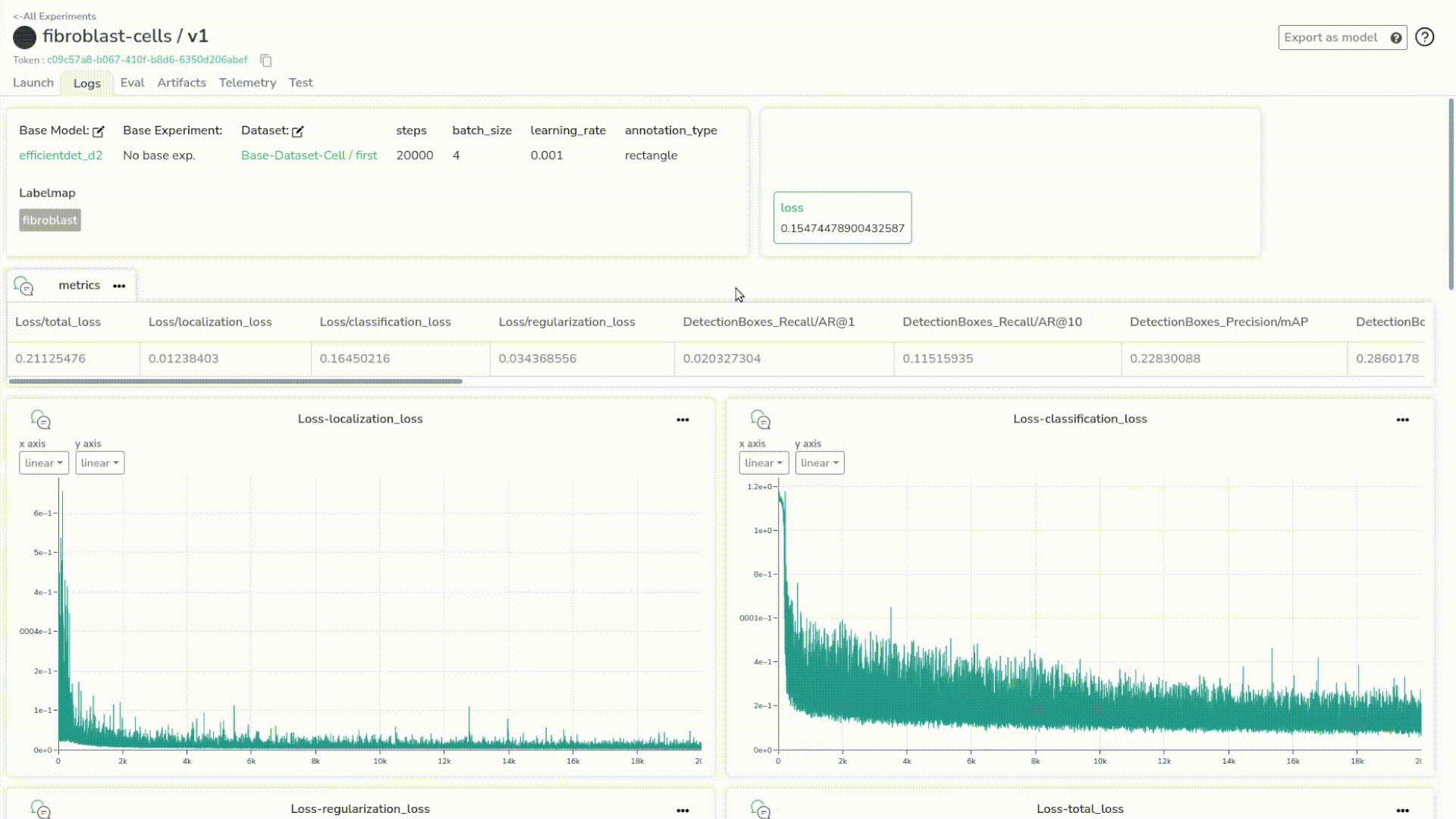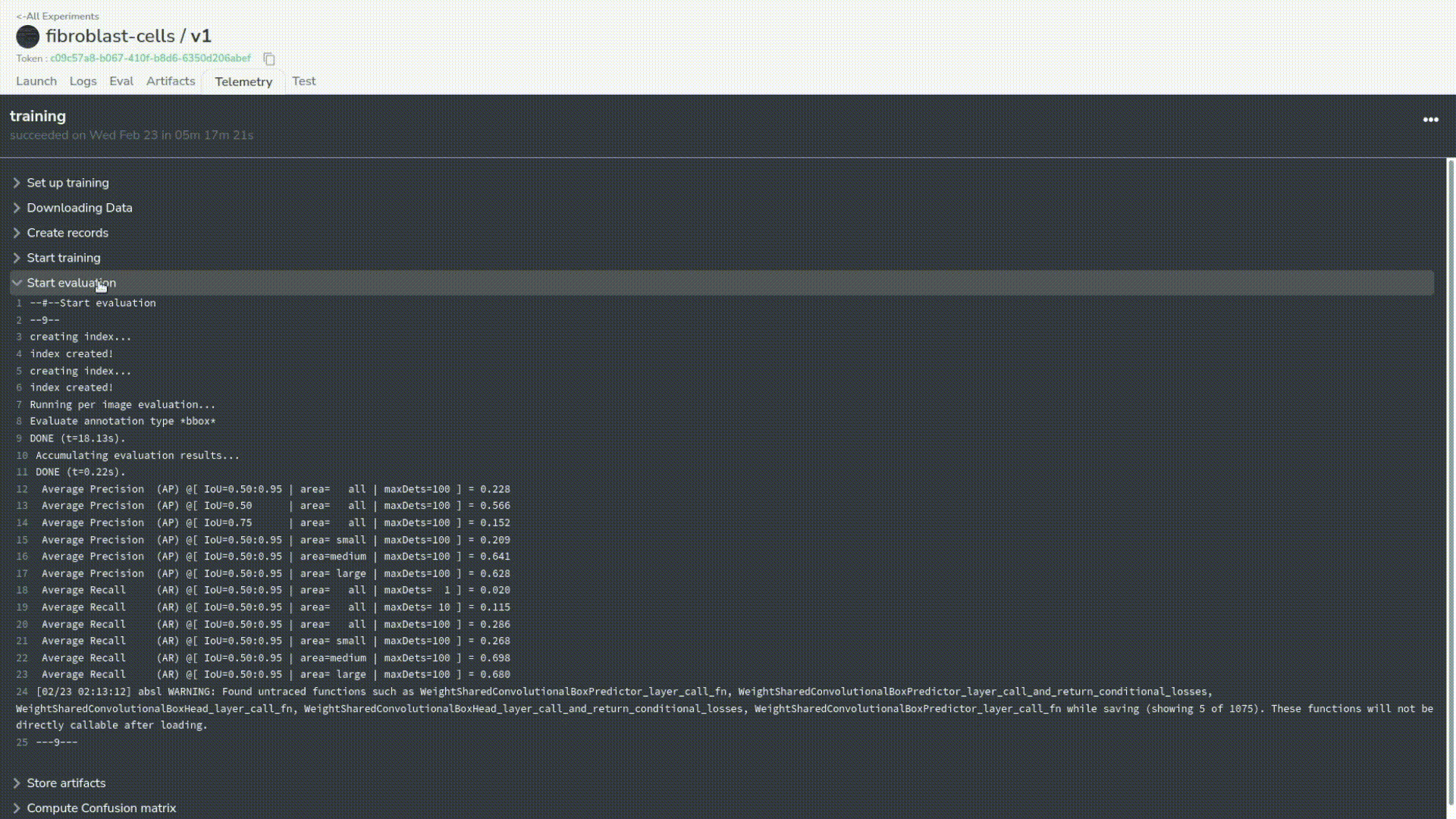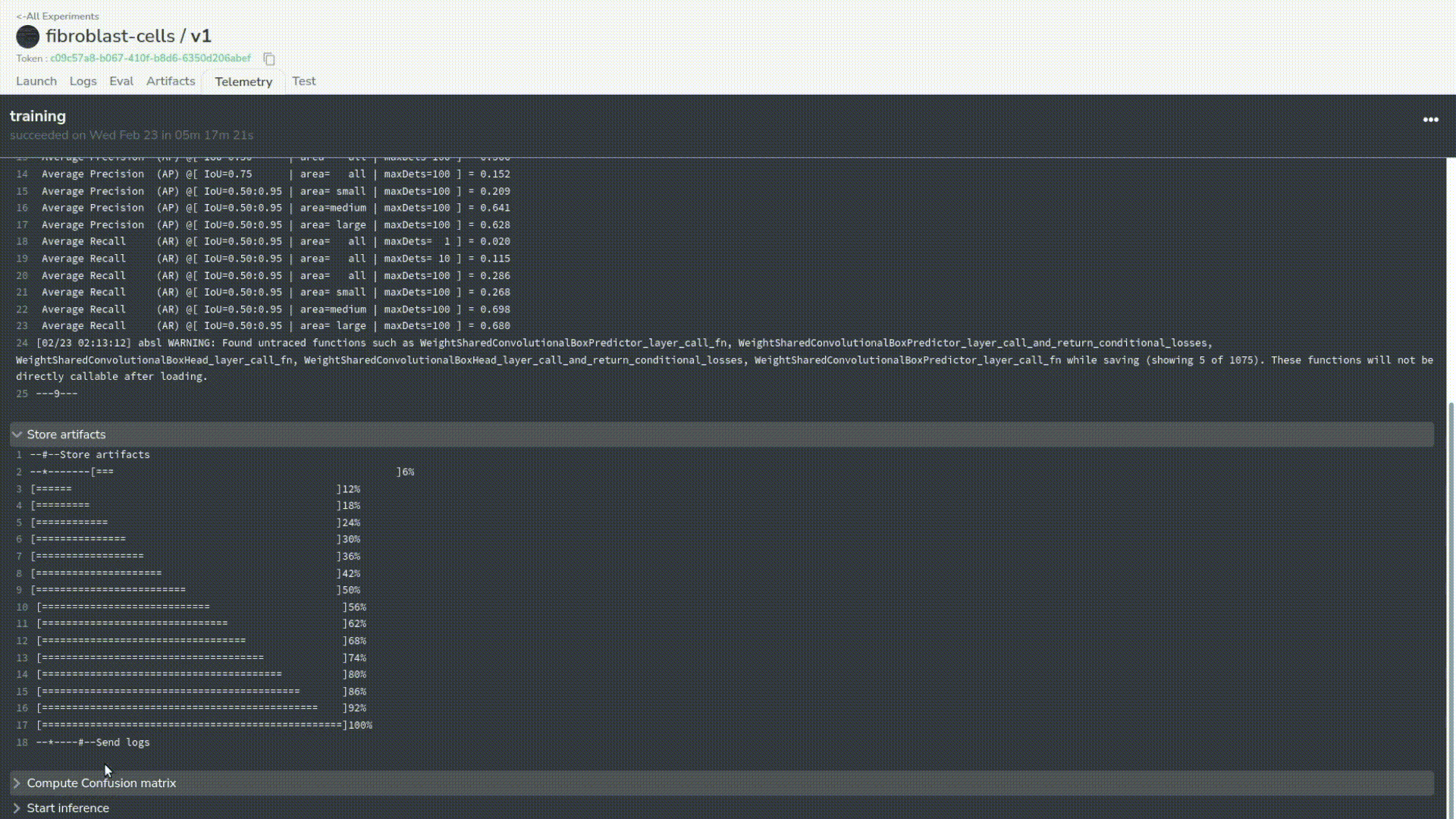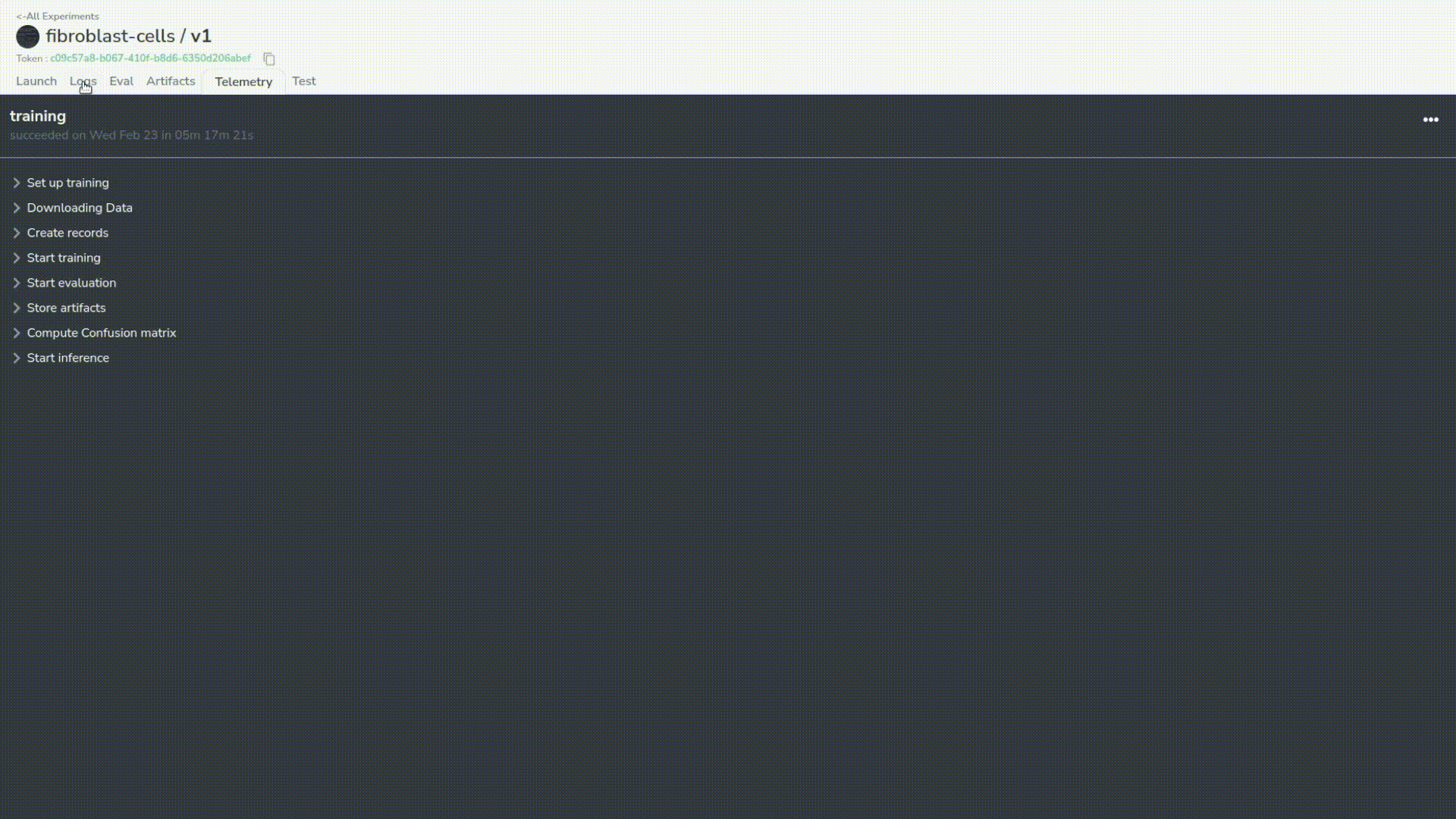
Again, we will also convert this experiment into a model in our registry.

Let’s create a new deployment!
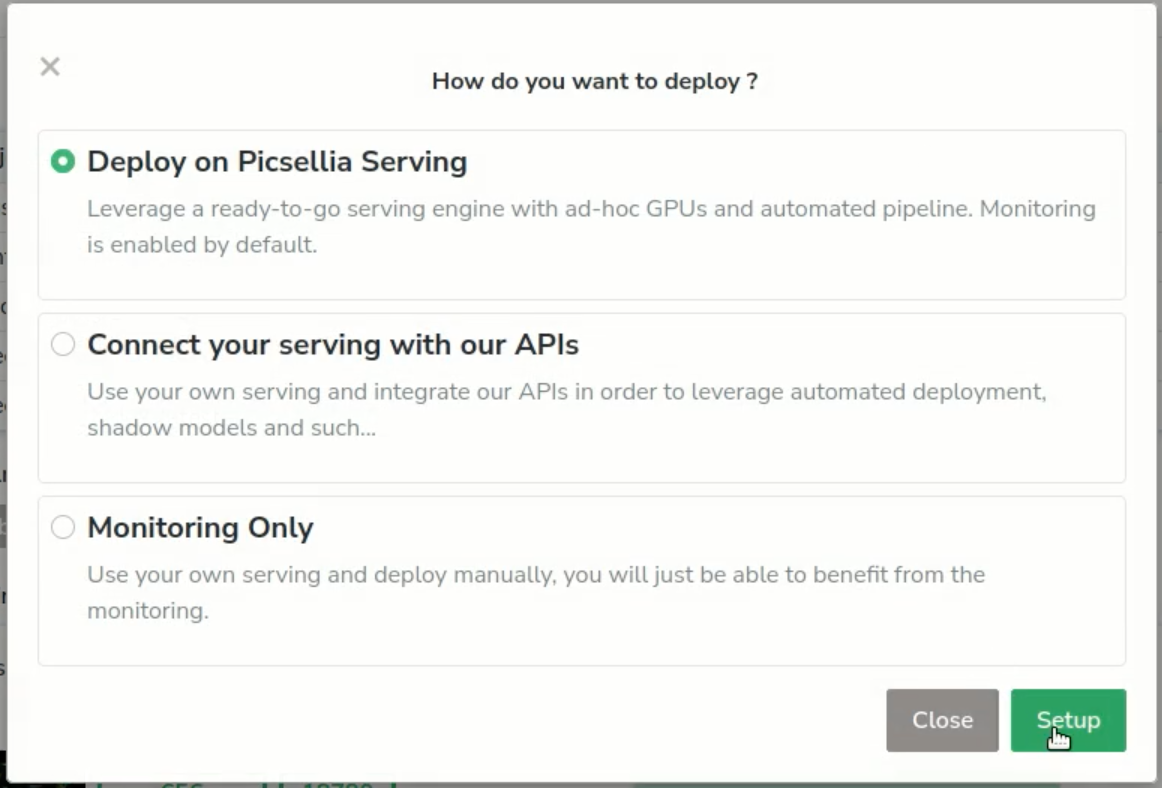
We’ll set our same confidence threshold as before.

Continuous training and alert system
Then we’ll head to our new deployment. Before launching some predictions, we will first set up our deployments with some new features different from the previous one: the continuous training and the alert system.
Just to give some context, the continuous training is the ability to watch a trigger that will launch a simple experiment; in our case with some predefined parameters, base model and dataset. As we have all of our assets centralized in Picsellia, it’s really easy to do so.
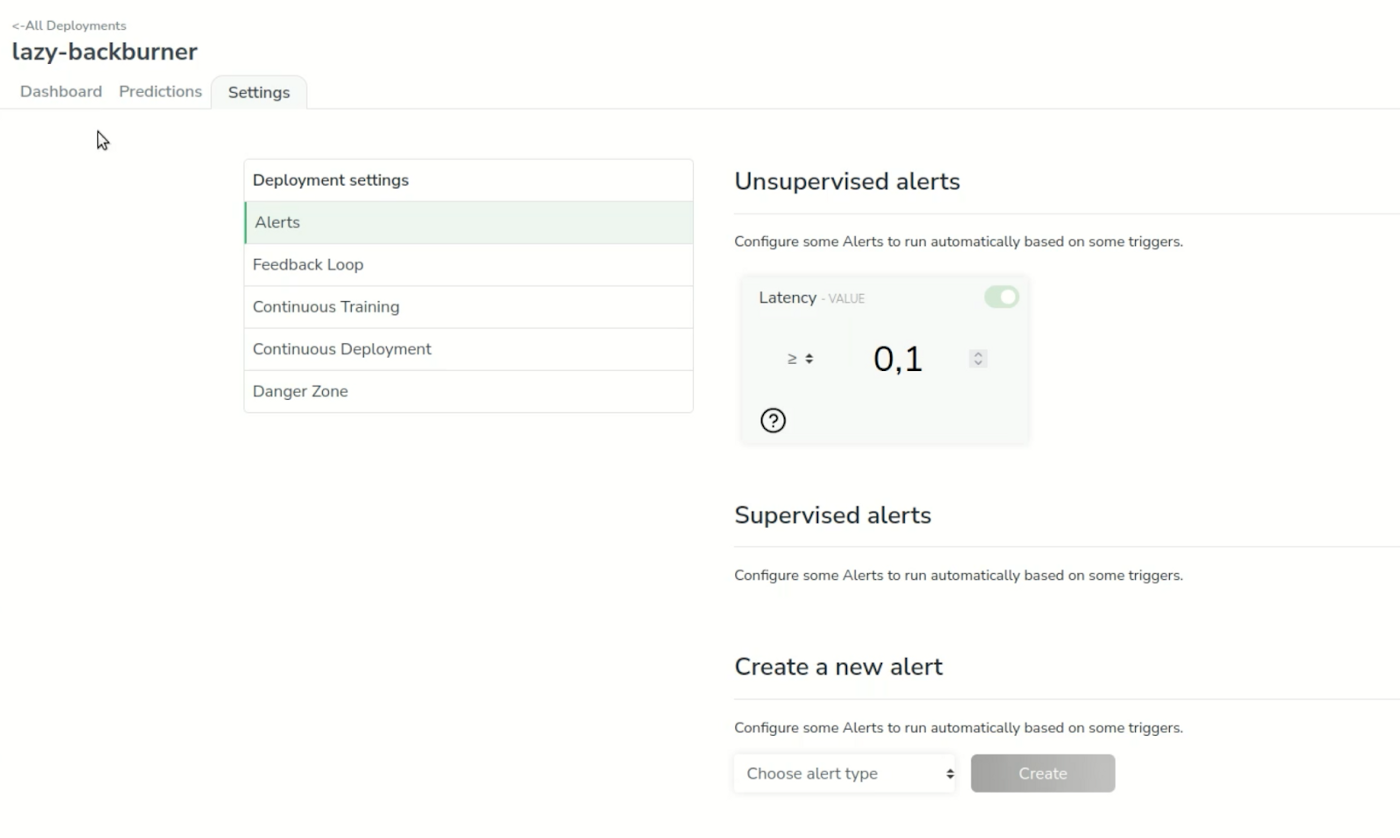
In our case, for the sake of the webinar, we want the continuous training loop to launch after 3 new samples from the predictions are reviewed. We also have a default alert on the latency of the model that will send us some notifications if the latency goes beyond 100ms.
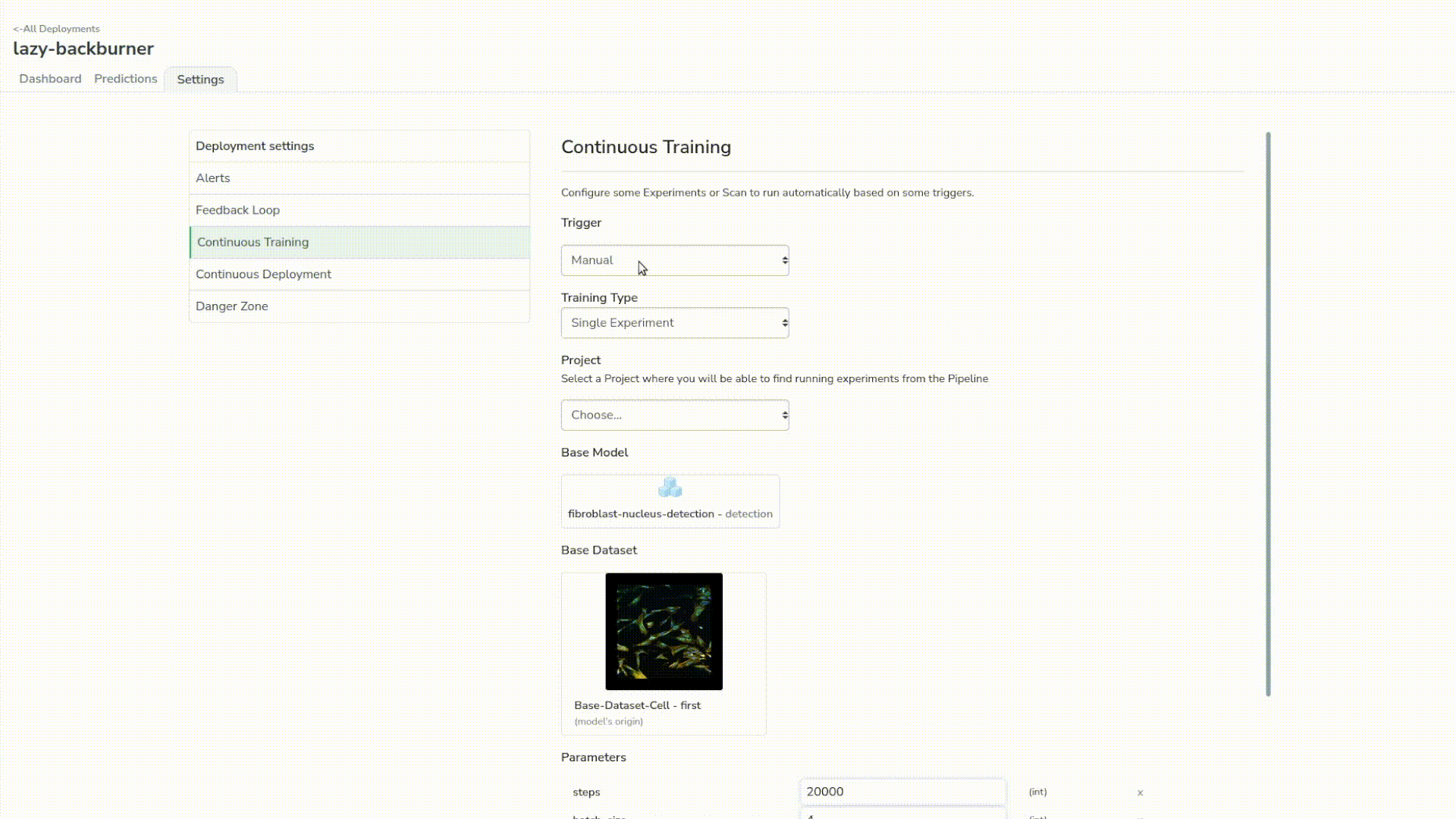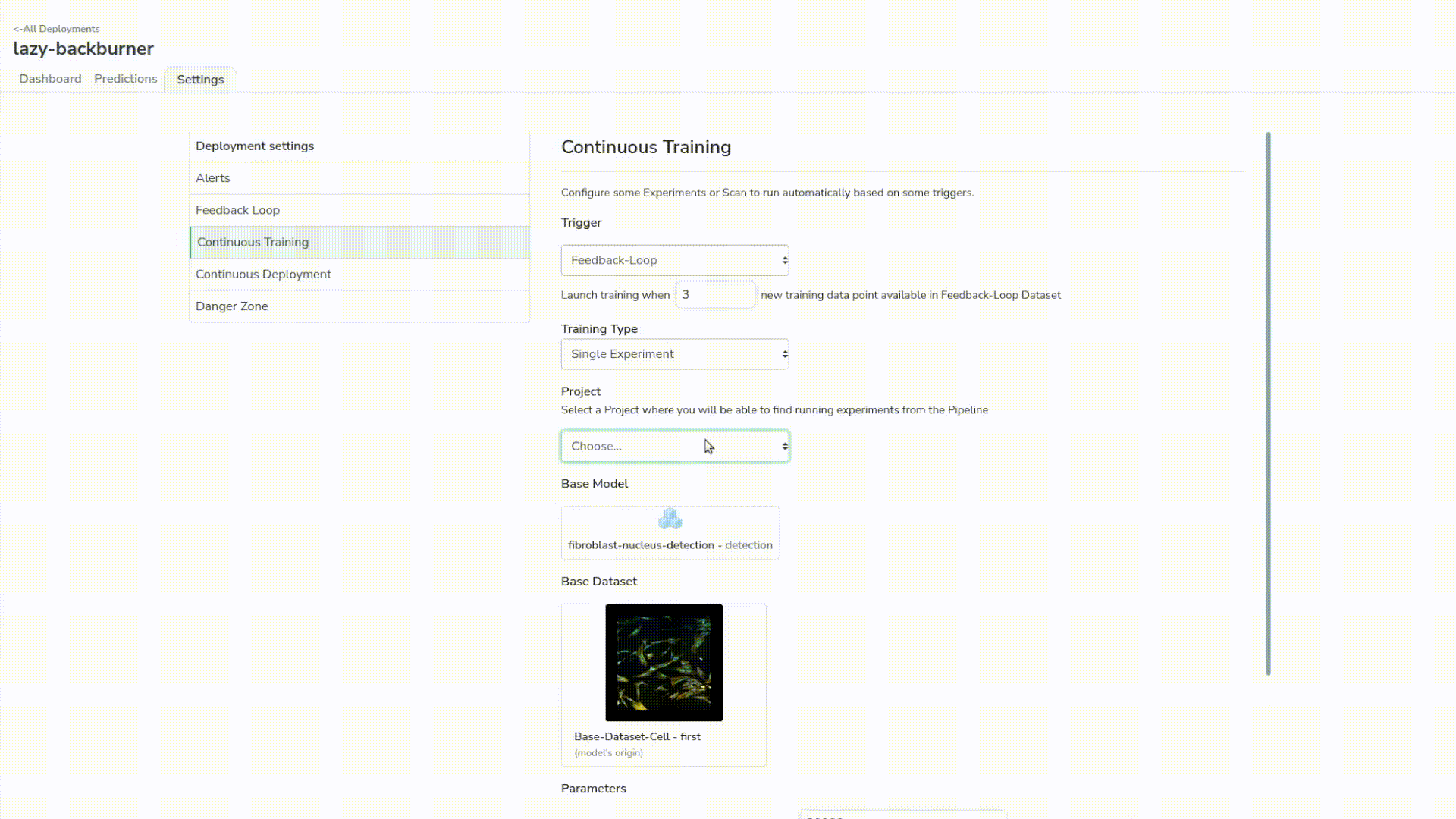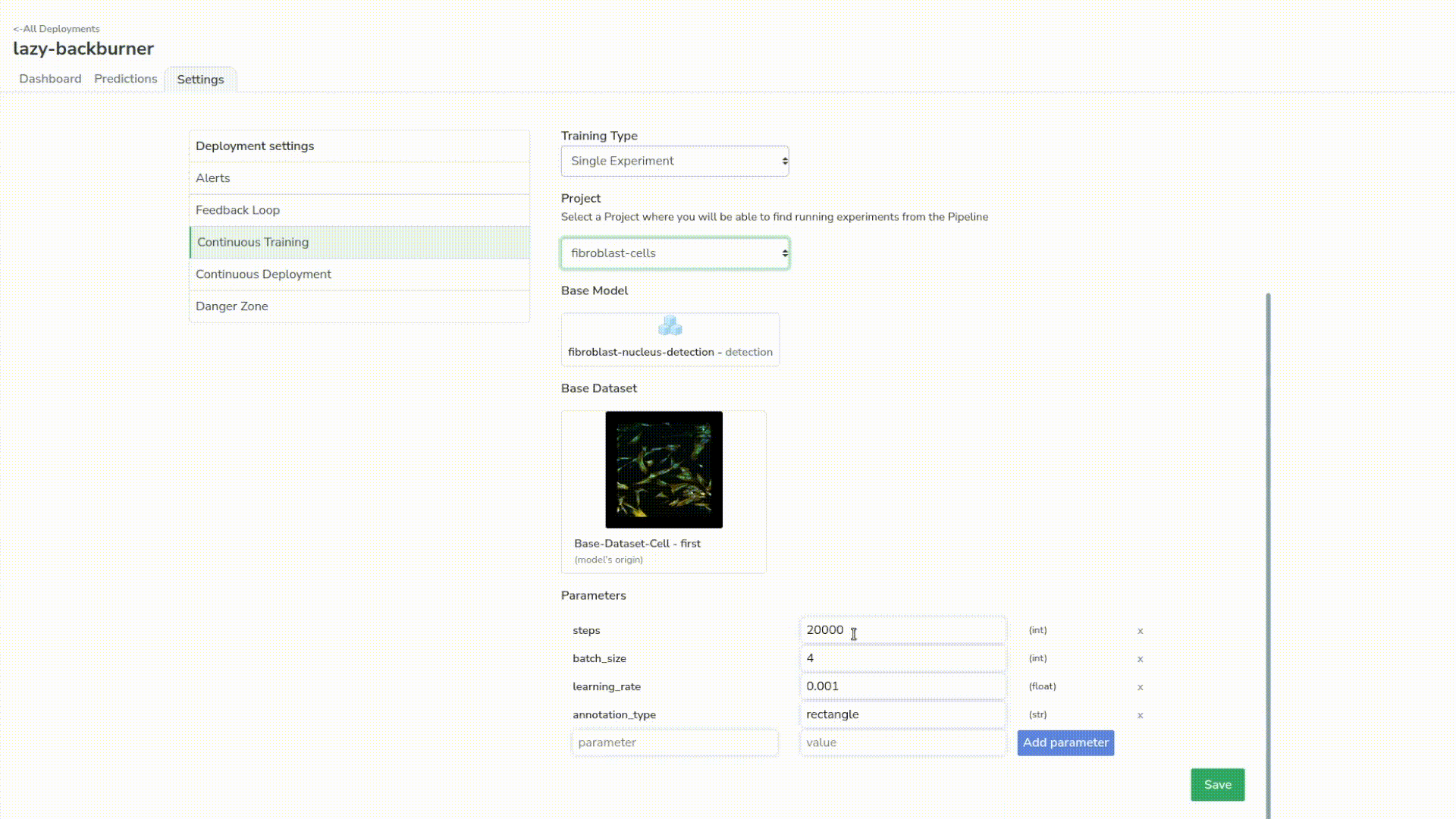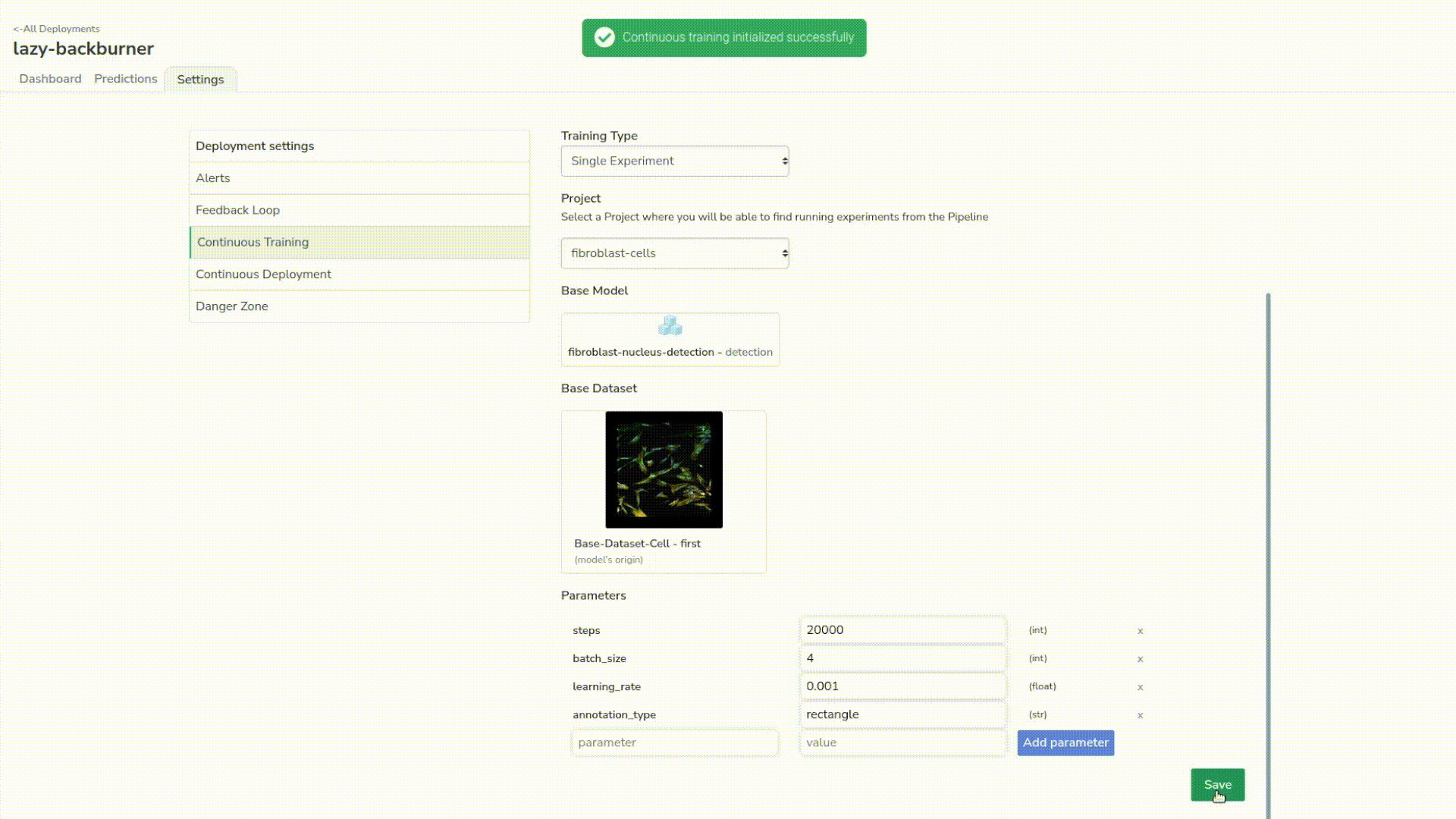
Now we’re going to set up default alerts that will be triggered on the latency of the model. If the model goes beyond 100 ms, we should see some alerts on the dashboard.
Now we are doing predictions with some original images that we kept on the side and see how our model performs. We can already see that our model triggered our alerts–its latency is 2 to 3 times greater than the 100 ms threshold we set earlier.
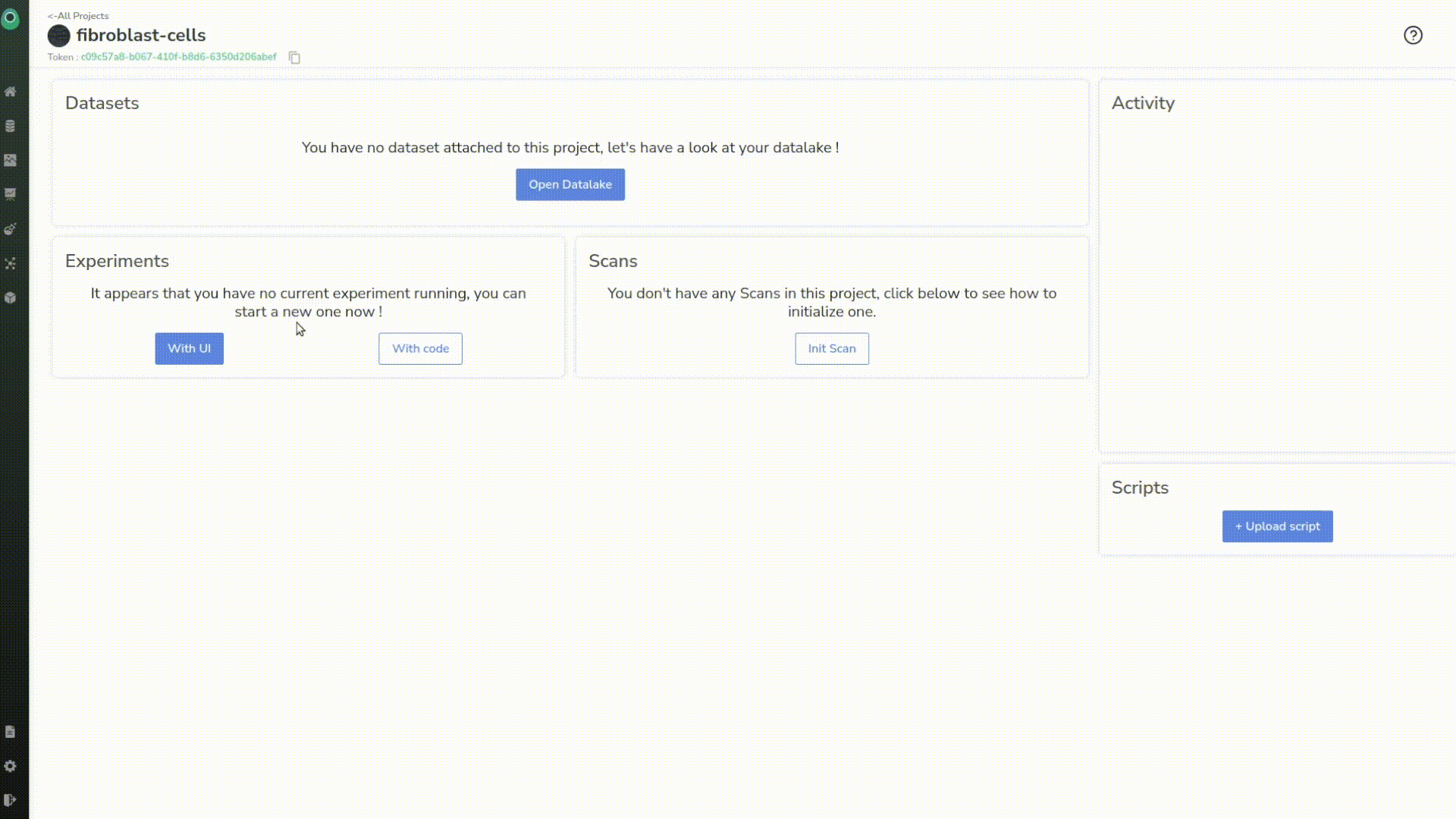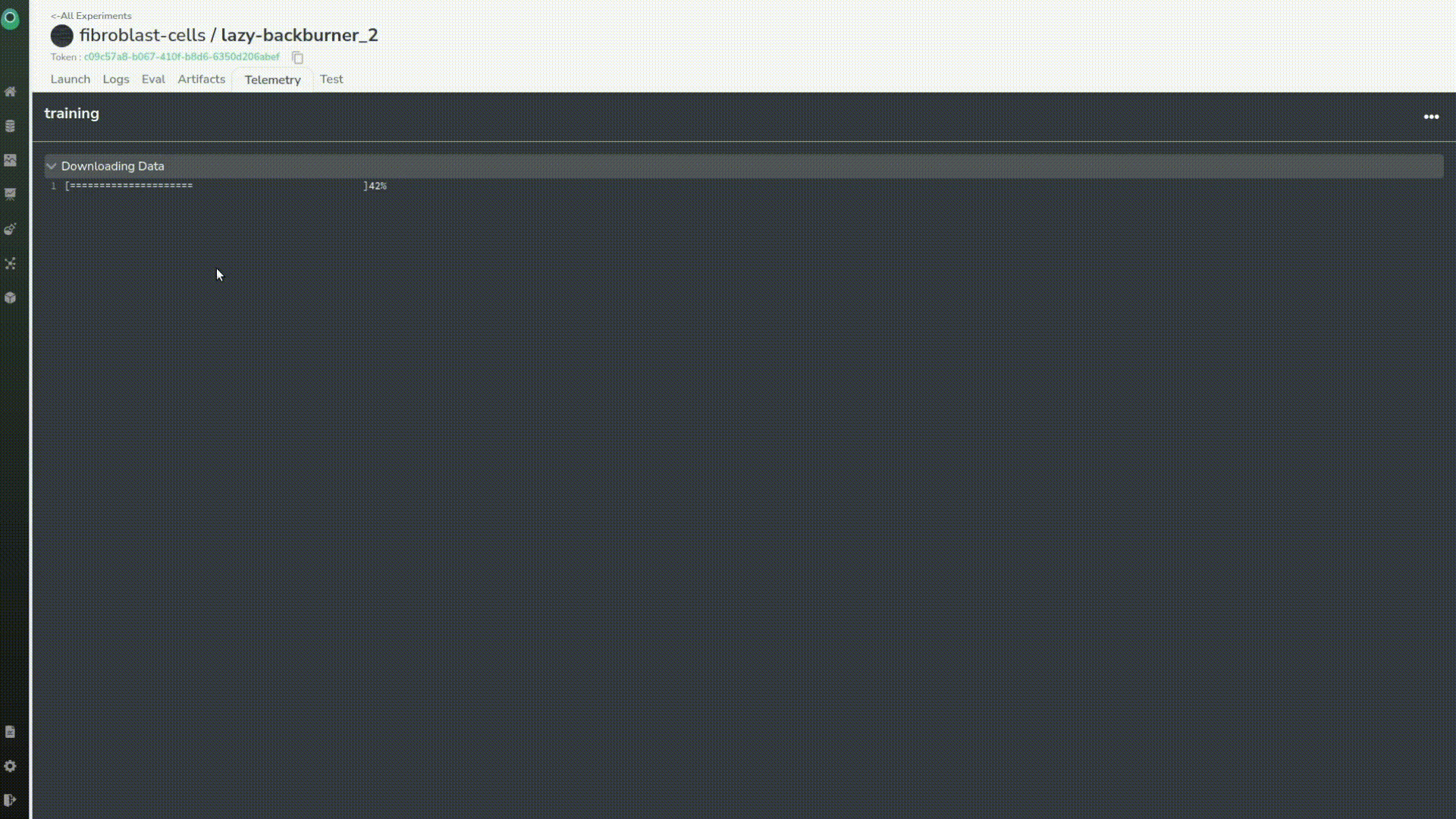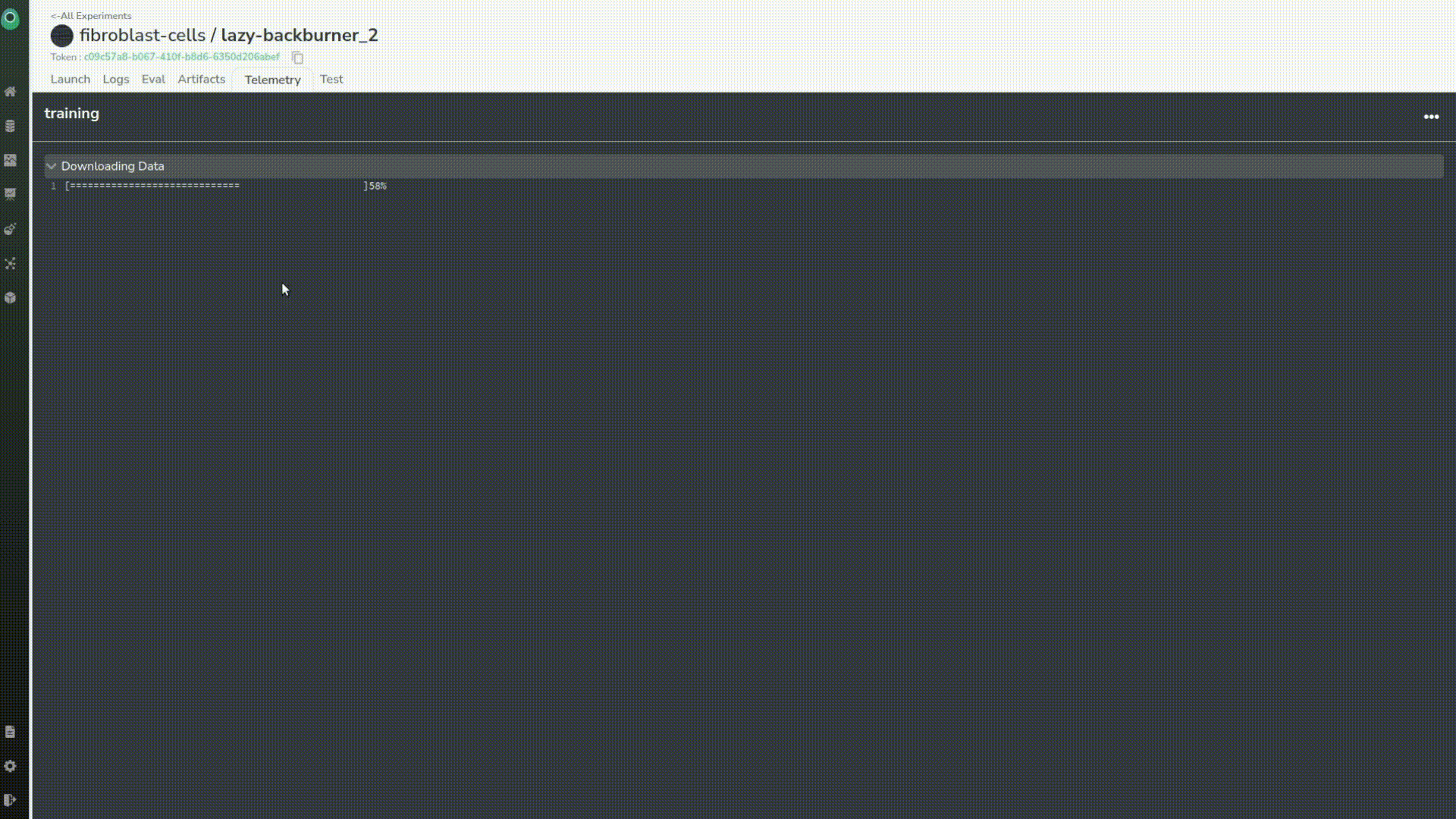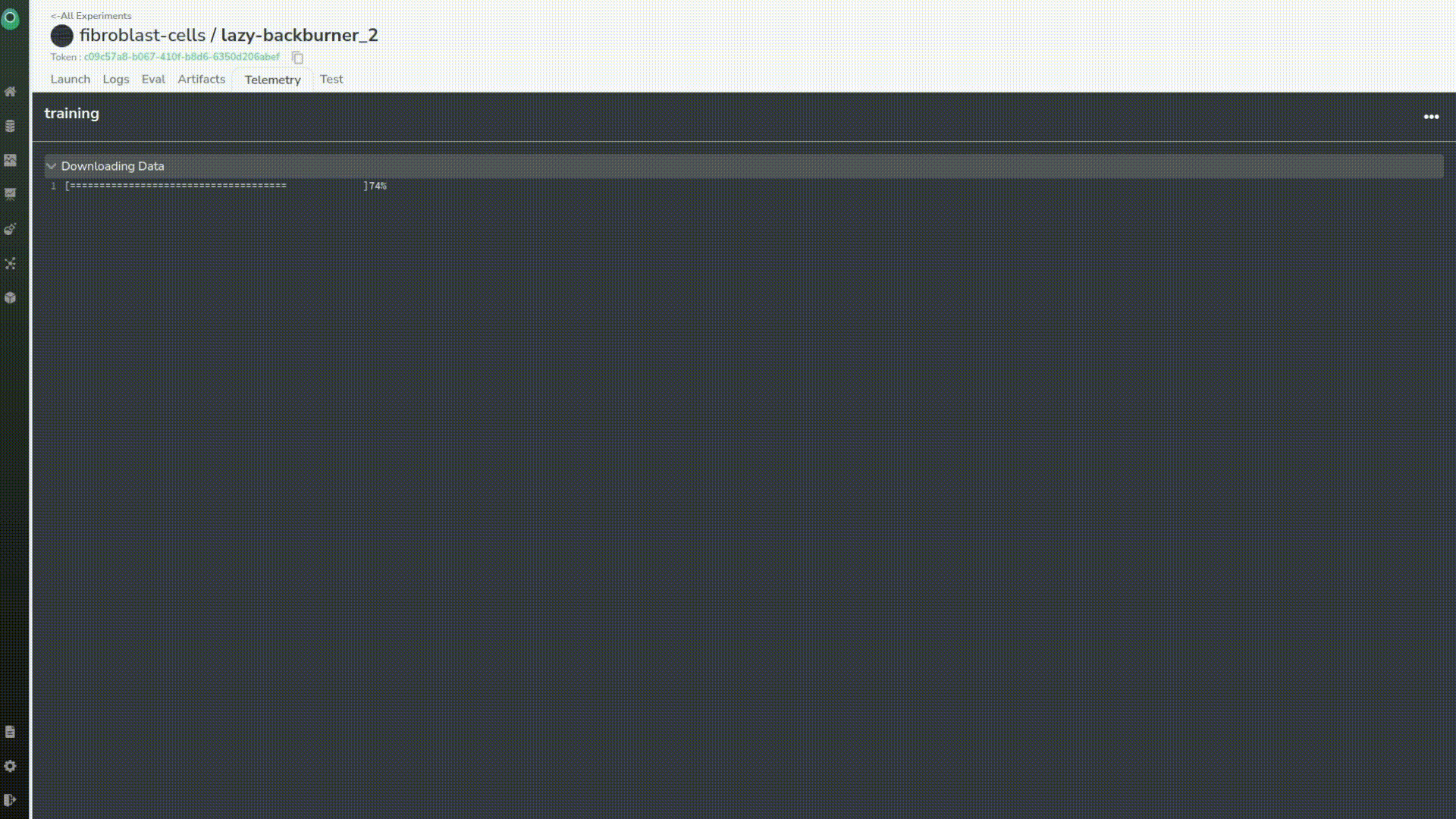
Next, we’ll review 3 images, in order to launch our continuous training loop.
Once we’ve done that, a training will be automatically launched in the project used to train the first model.
And, a couple of minutes later we can see that our experiment status is a success!

This means that if we go back to our deployment, we should see something new.

Comparing shadow models
The tab at the top of the screen is telling us that we have a new model ready from the continuous training loop, that can be deployed.

We will deploy it as a shadow model to see how it performs against our first and current production model. In short, the shadow model will only be there to understand if it performs better than the other.
The model has been deployed successfully. Now we will make some predictions again, and we can see that we can directly compare our production model with the shadow model with no effort.
It looked like the shadow model had some latency issues at first but now has the same latency as our first model. And, if we take a closer look we can see that the mean latency of the shadow model is even better than the original one of tens of milliseconds.
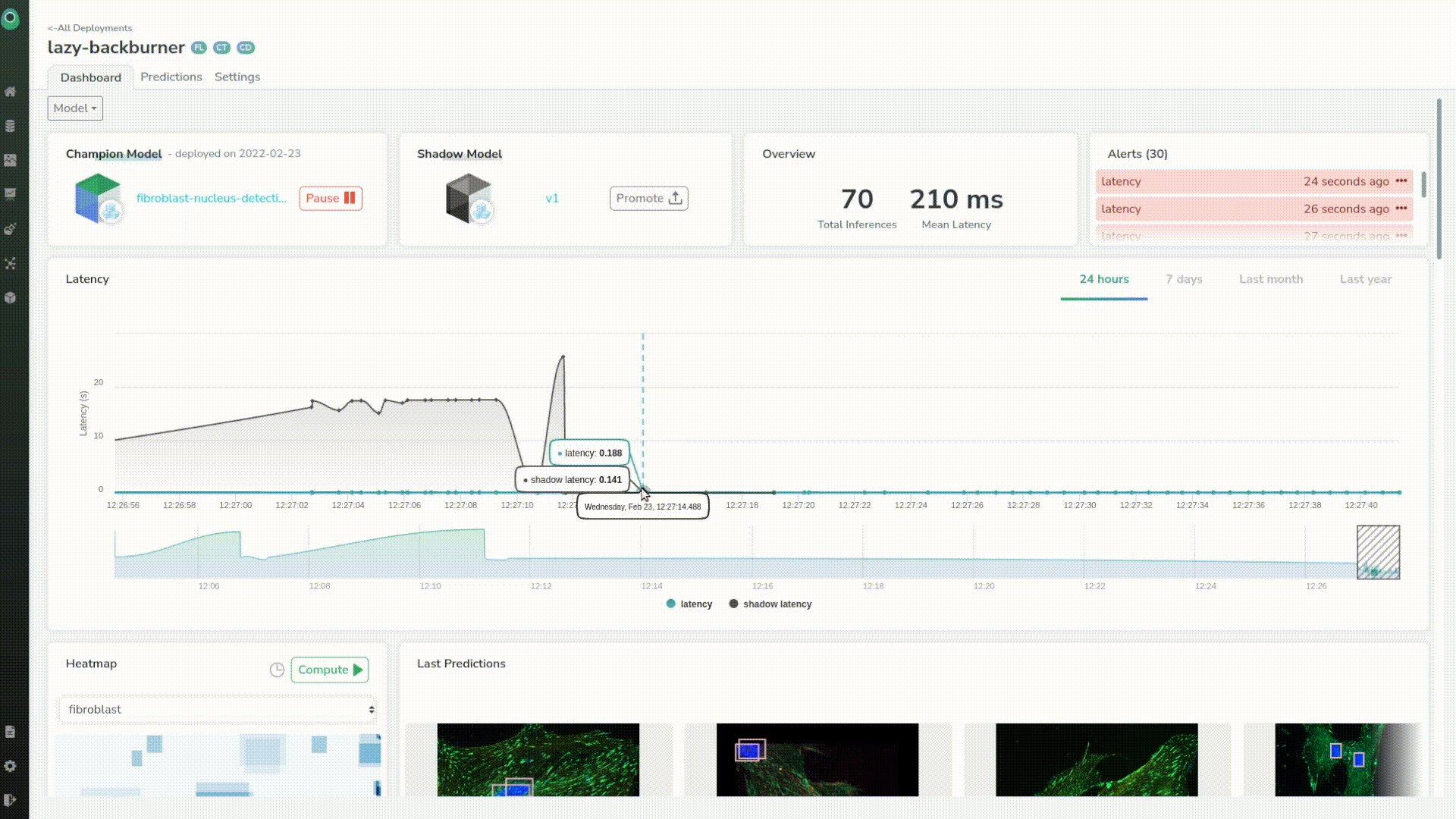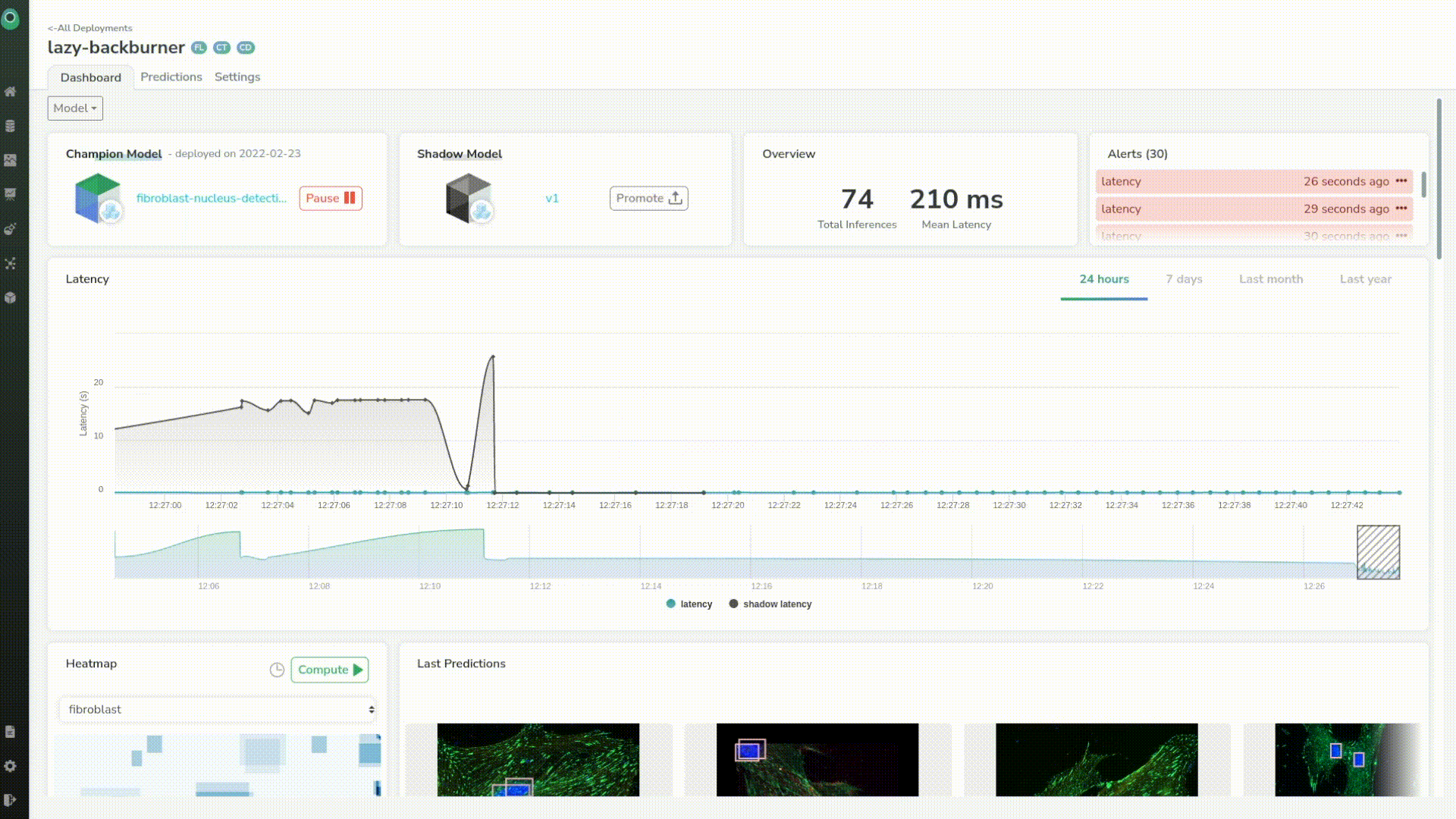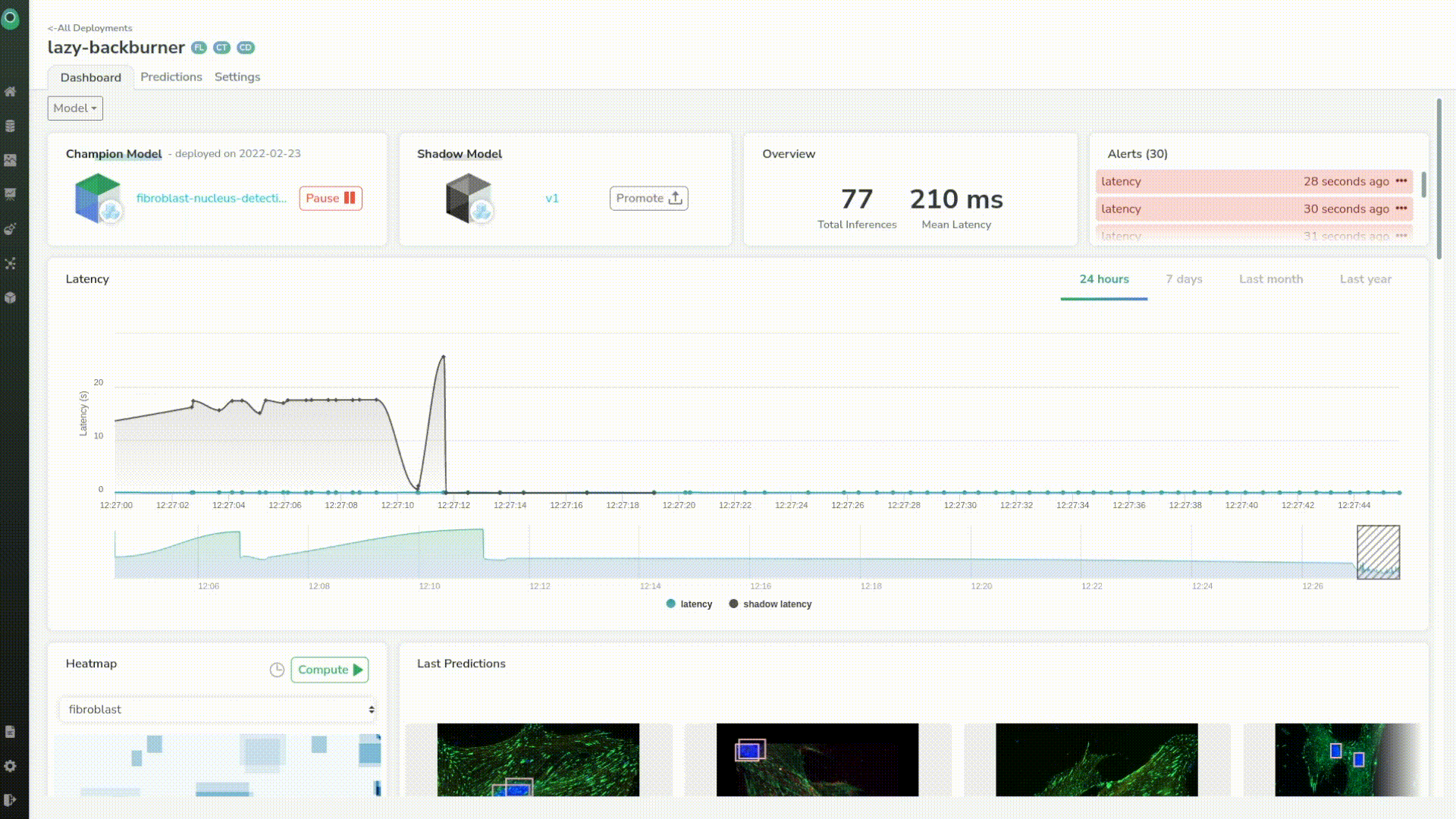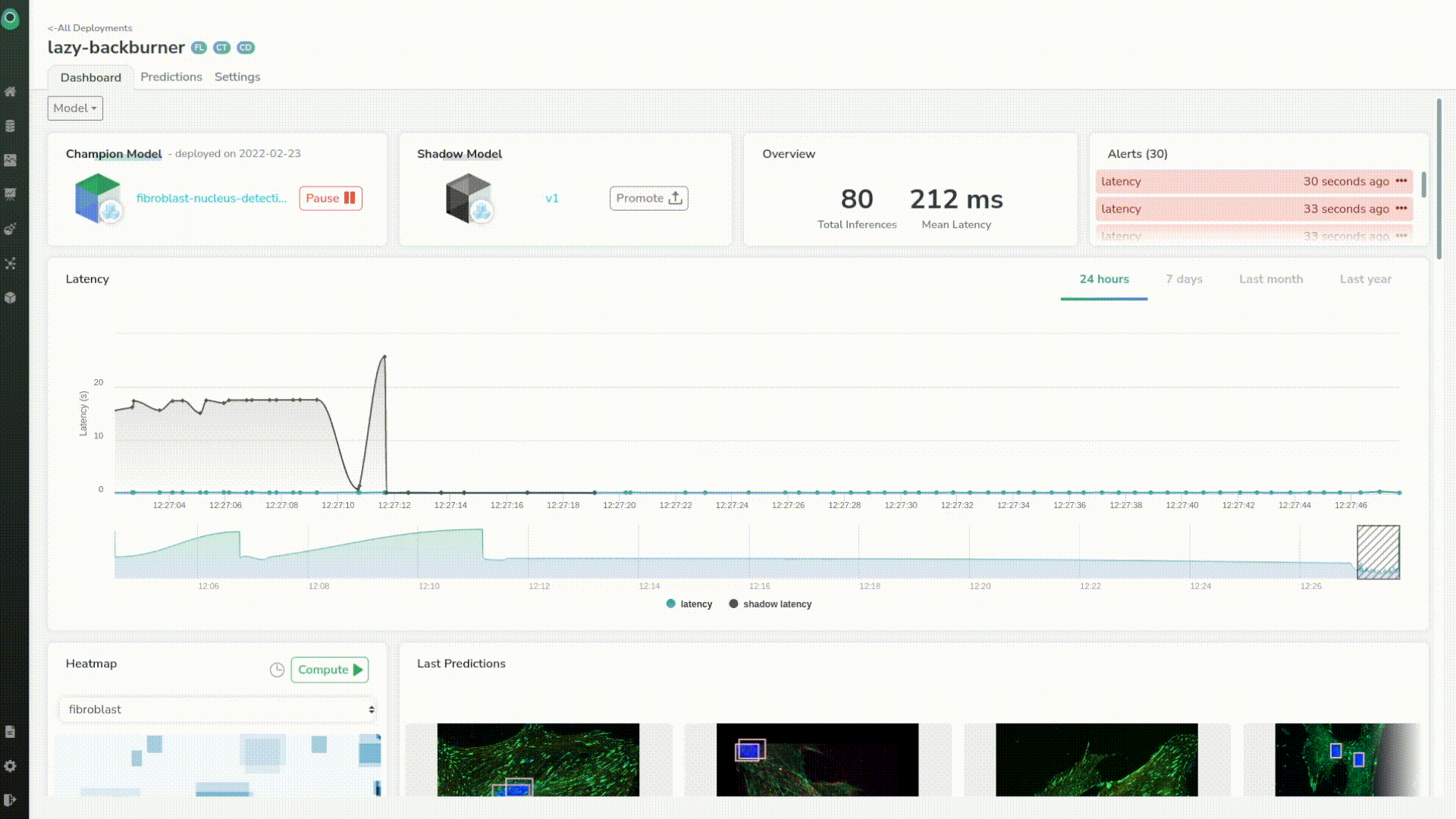
If we want we can investigate a particular prediction by just clicking on any point in the chart. This helps us identify and better understand outliers coming from the prediction.
We can see that our shadow model seems to perform a little bit better than the previous one, just judging by its latency.
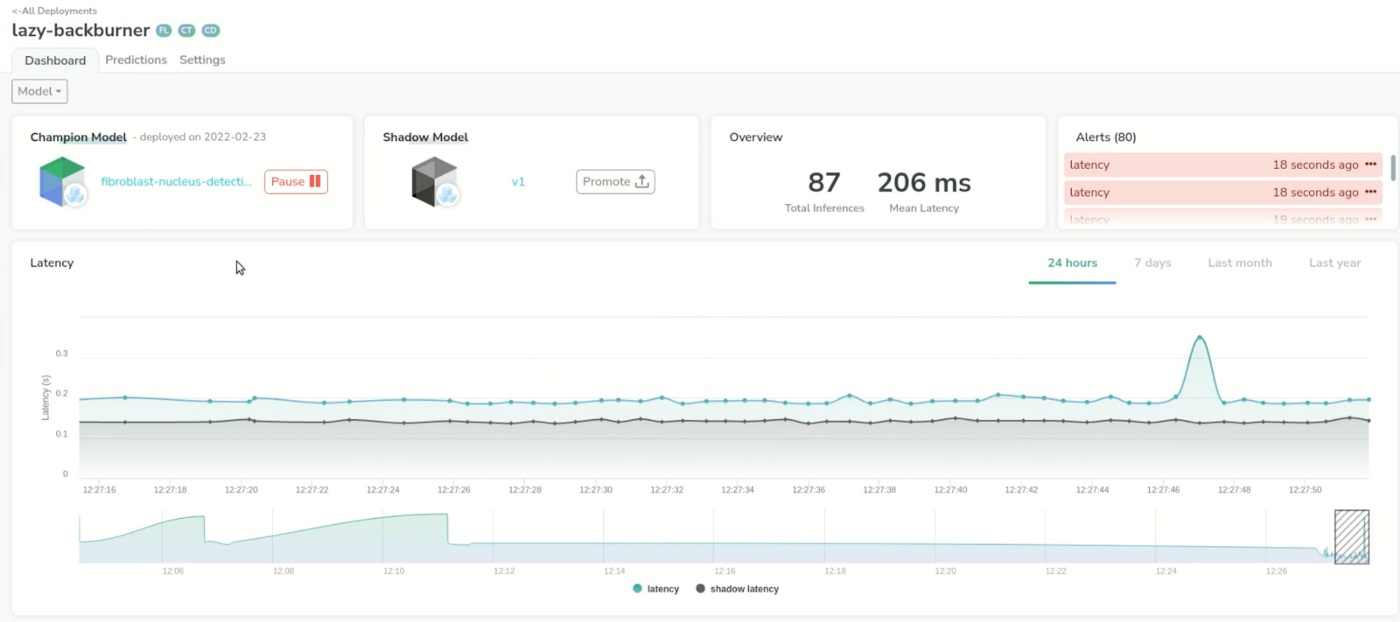
We can go back to our prediction tab one last time and start to review some images to ensure the quality of the predictions of the shadow model–the same ground-truth will be compared between the prediction of the original model and the shadow model.
We can see that we have new metrics again in our dashboard, with information about the shadow model. This will help us to make the best decision on when to deploy the new model to production.
Here, if we just base our decision on the latency, we choose to promote the shadow model as a champion, and thus, our old model is no longer the production model and has been replaced by our shadow model.
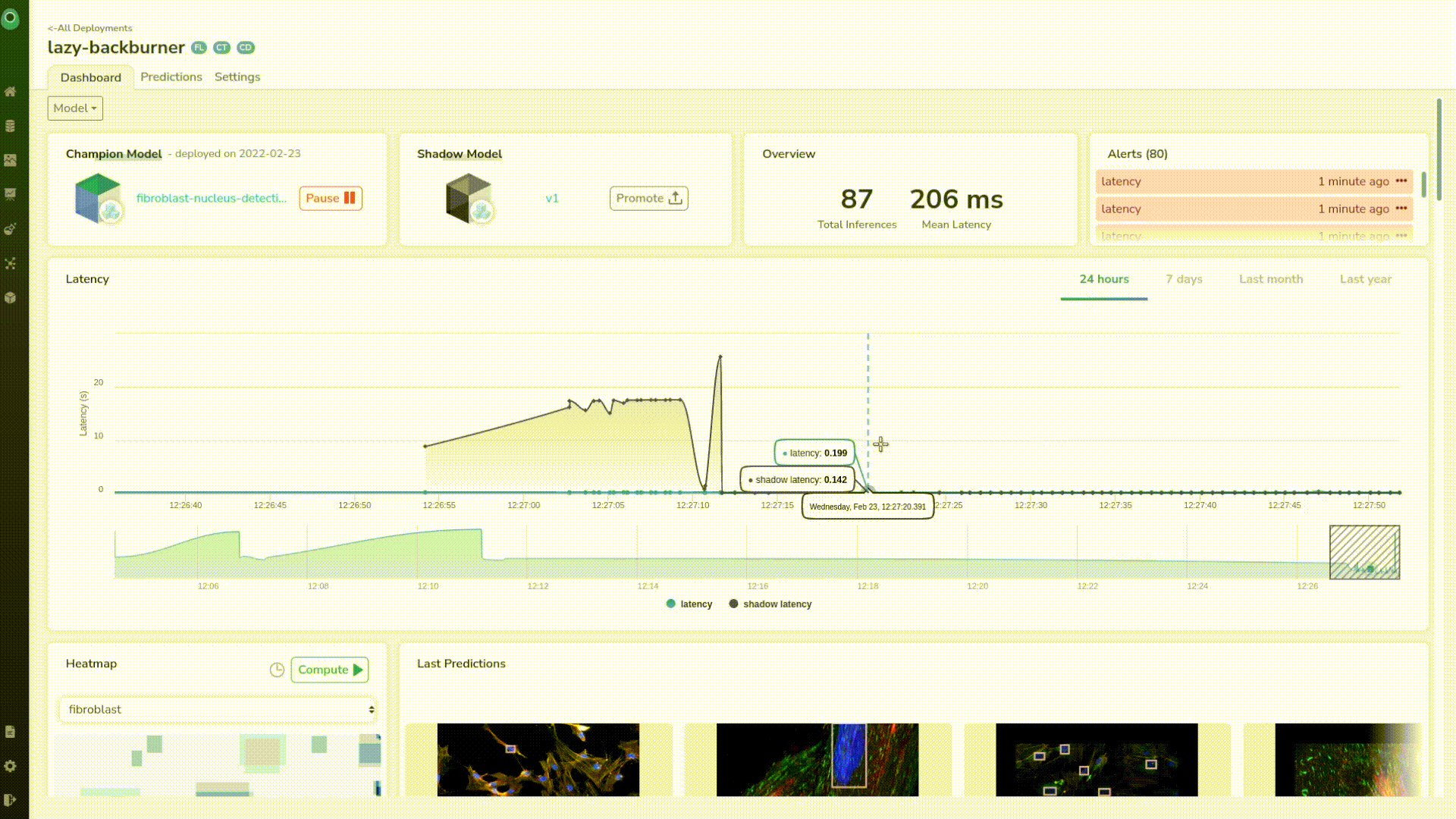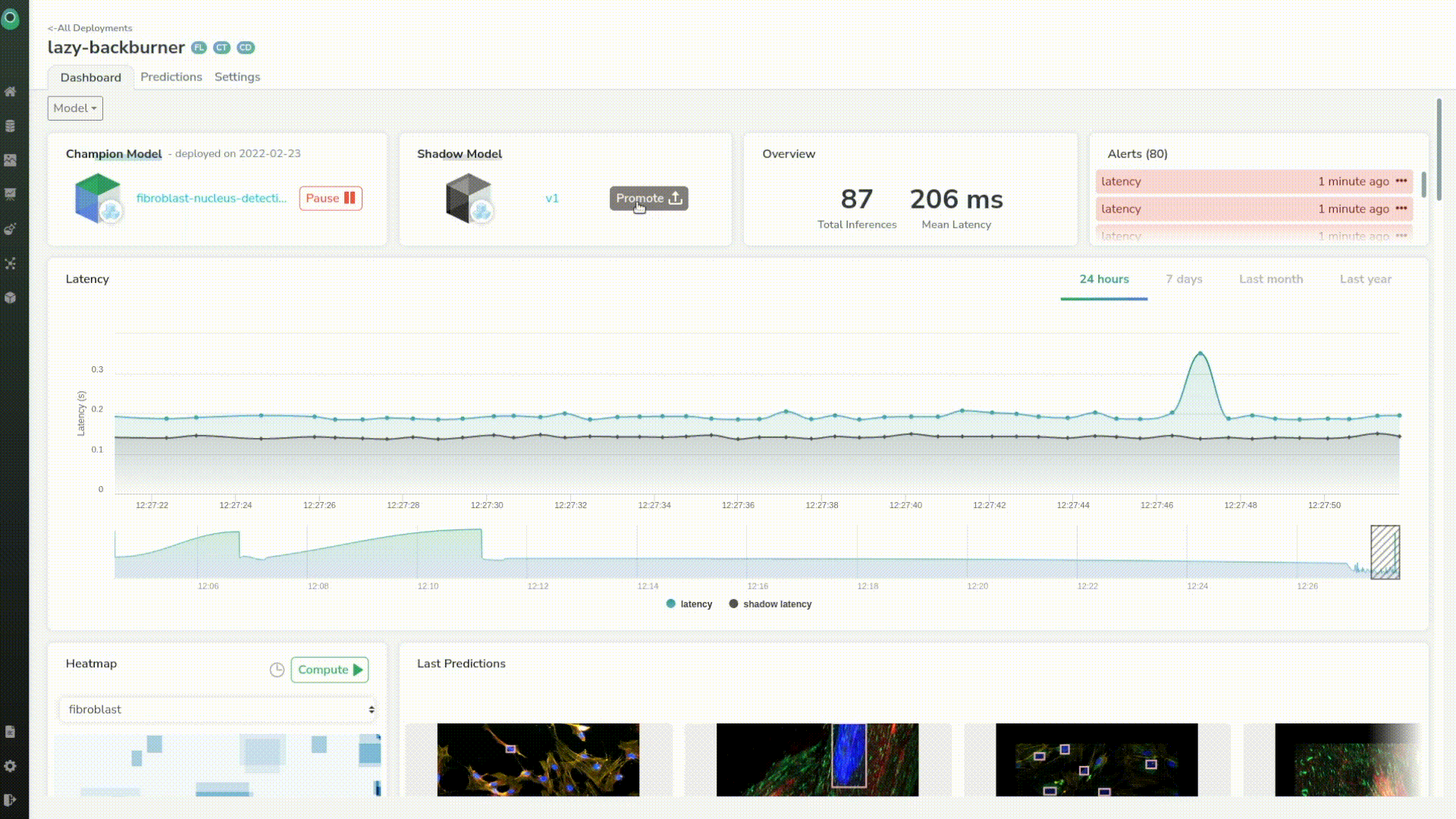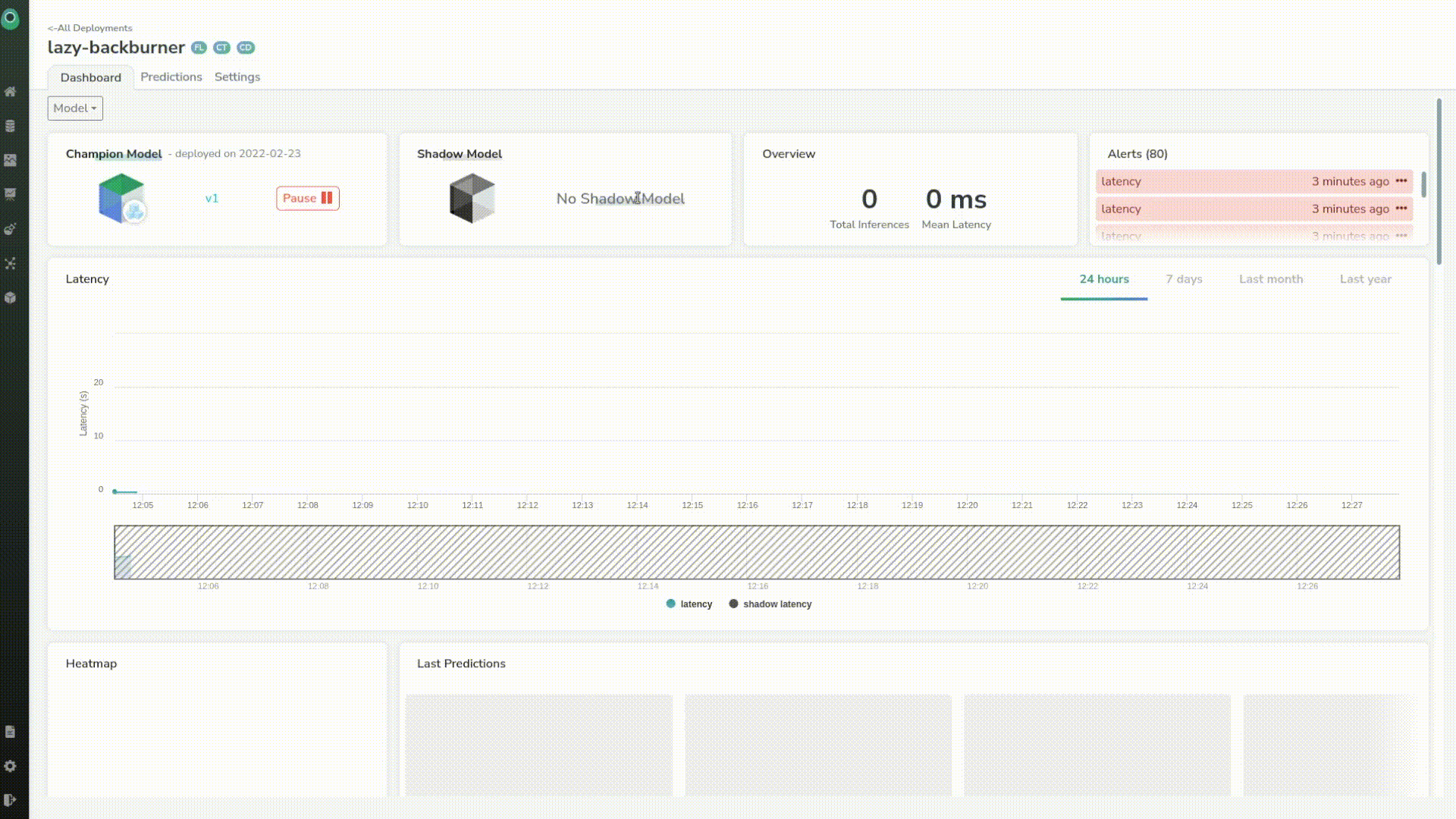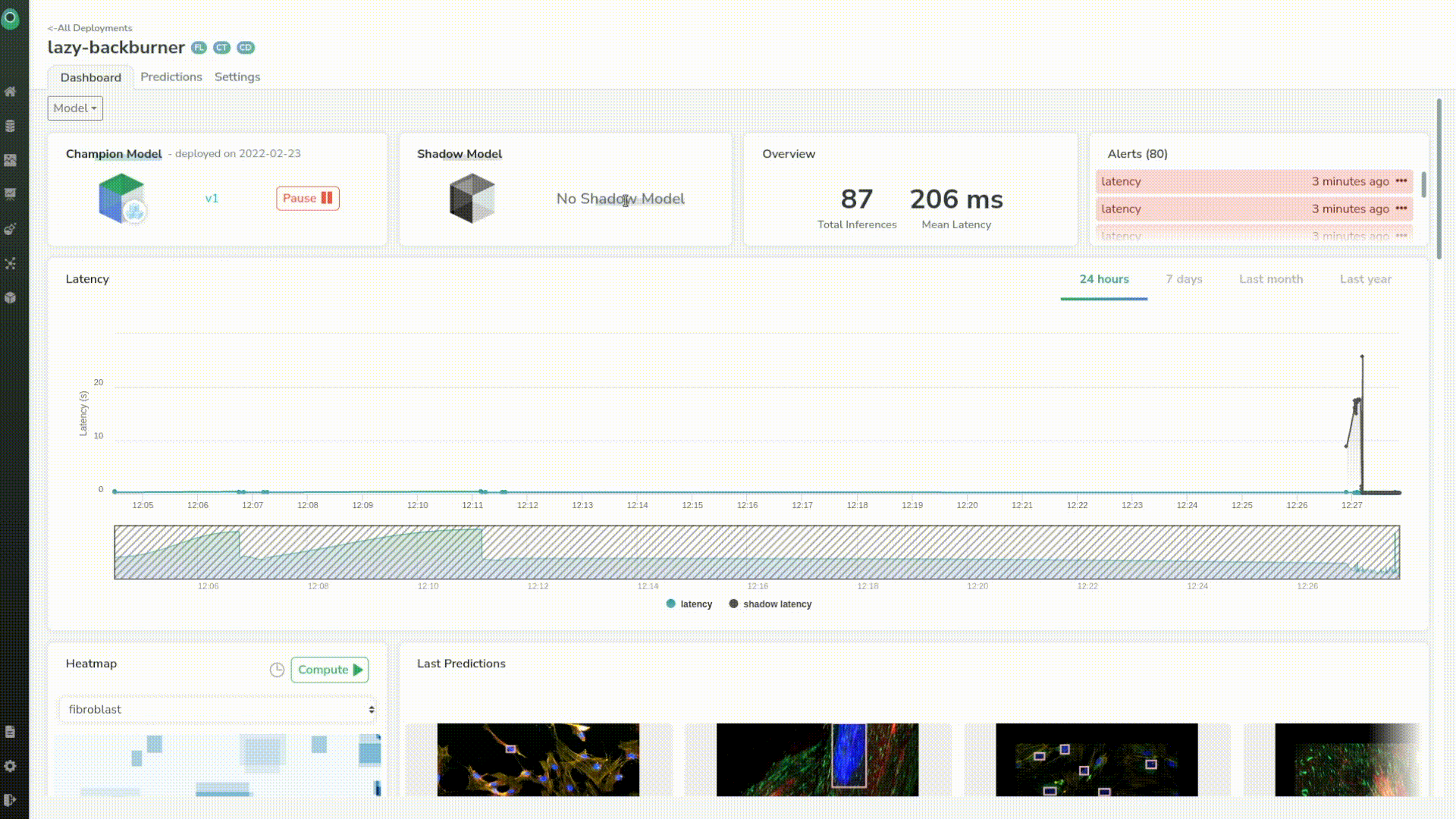
Finally, this closes the loop from training data, to deployment and monitoring for computer vision, which is what we call CVOps.
In case you’d like to try Picsellia for free, you can directly book a quick call here so we can set you up!


